Pour la version française cliquez ici
Für die deutsche Version klicken Sie hier

with many thanks to my media team (and now fellow shareholders) who have made the year so successful and fulfilling:
Eric De Grasse, Chief Technology Officer
Catarina Conti, Media Content Manager/Media Analytics
Gregory Lanzenberg, Media/Video Operations Coordinator
Alexandra Dumont, Operations Manager of The Project Counsel Group
Angela Gambetta, Manager of E-Discovery Operations
with a very special thanks to videographer extraordinaire Marco Vallini and the video crew,
plus my graphics designer Silvia Di Prospero
and … thanks to my readers from Australia, Belgium, Canada, China, France, Germany, Greece, Ireland, Italy, South Africa, the United Kingdom, and the United States … you were my top countries for
readership. I appreciate you taking the time to read (yet another) perspective on tech and other stuff from a guy who lives on multiple shores
* * * * * * * * * *
“Scientific topics receiving prominent play in newspapers and magazines over the past several years include molecular biology, artificial intelligence, artificial life, chaos theory, massive parallelism, neural nets, the inflationary universe, fractals, complex adaptive systems, superstrings, biodiversity, nanotechnology, the human genome, expert systems, punctuated equilibrium, cellular automata, fuzzy logic, space biospheres, the Gaia hypothesis, virtual reality, cyberspace, and teraflop machines. … Unlike previous intellectual pursuits, the achievements of this technical culture are not the marginal disputes of a quarrelsome mandarin class: they will affect the lives of everybody on the planet.”
12 January 2018 (St Malo, France) – You might think that the above list of topics is a part of a piece written last year, or perhaps a very recent past year. But you would be wrong. It was the central point in an essay published 25 years ago in The Los Angeles Times by John Brockman, a literary agent (best friends with the likes of Andy Warhol and Bob Dylan) and author specializing in scientific literature, most famous for founding the Edge Foundation, an organization aimed to bring together people working at the edge of a broad range of scientific and technical fields. If you ever get invited to an Edge dinner or event, just go. You might find yourself sitting next to Richard Dawkins, Daniel Dennett, Jared Diamond, John Tooby, David Deutsch, Nicholas Carr, Alex Pentland, Nassim Nicholas Taleb, Martin Rees, A.C. Grayling, etc. Or all of them.
Brockman certainly got it right. But he may not have been able to predict the dizzying pace. And this year? Look, I don’t know how else to say this: it’s been a hell of a year. The tech news/announcement cycle moves so fast that by the time it takes to research, write, reflect, edit, and publish, it’s already yesterday’s news. And in 2017, yesterday’s news might as well be last year’s news.
And not just tech. In a world where people are worried about what bad thing could happen to them next, it’s been difficult for me to write about what’s happening on distant battlefields or in the abstract within the national security/surveillance apparatus.
Yes, the breathtaking advance of scientific discovery and technology has the unknown on the run. Not so long ago, the Creation was 8,000 years old and Heaven hovered a few thousand miles above our heads. Now Earth is 4.5 billion years old and the observable Universe spans 92 billion light years. But I think as we are hurled headlong into the frenetic pace of all this AI development we suffer from illusions of understanding, a false sense of comprehension, failing to see the looming chasm between what our brain knows and what our mind is capable of accessing. It’s a problem, of course. Science has spawned a proliferation of technology that has dramatically infiltrated all aspects of modern life. In many ways the world is becoming so dynamic and complex that technological capabilities are overwhelming human capabilities to optimally interact with and leverage those technologies.
As my regular readers know I try to be a “Big Picture” guy, being an opsimath at heart and believing everything in technology is related. The model I try to follow is like the British magazine tradition of a weekly diary – on the issue, but a little distant from it, personal as well as political, conversational more than formal.
To do that, I pursue a very eclectic conference schedule that covers 18+ events (my team covers another 8+ events) and provides me perspective and a holistic tech education. You can see my annual conference schedule by clicking here. Call it my personal “Theory of Everything”. Although if you are not careful you can find yourself going through a mental miasma with all this overwhelming tech.
But much of this technology I have taken on board in my day-to-day operations and much of it I have learned best I can by “doing it”, taking the old Spanish proverb to heart:

Because writing about technology is not “technical writing.” It is about framing a concept, about creating a narrative. Technology affects people both positively and negatively. You need to provide perspective.
Having a media company, attending all of these wonderous technology events, you meet people like Tom Whitehall, a “reformed journalist/lawyer” who is now a hardware designer who can actually demystify the “innovation process” (yes, that intolerable phrase). He provides brilliant basics and a clear vision to companies to really, really innovate. Like me, Tom receives a firehose of “content” (as writing or video or photography is now called) which he reduces to a “52 things I have learned” list at the end of each year. With his kind permission I co-opted his title a few years ago and while our sources sometimes overlap (we attend many of the same events), we have different take-aways from these conferences.
Onto my “52 things I learned ….” starting with the big stuff:
– AI’s attempt to mimic the brain is so damn hard
– the Chinese will surpass the West in the development of artificial intelligence
– algorithms that summarize lengthy text are becoming better, as is language translation software
– the e-discovery ecosystem finally meets its demon
– computational propaganda and the end of truth
1. MIMICKING THE BRAIN
At too many so many of these conferences there was an overwhelming presentation of the AI in-progress that attempts to mimic the brain. And oh, boy, that is so difficult. I thought of visual illusions such as the Necker Cube
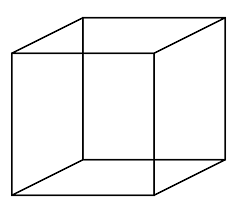
and the Penrose Impossible Triangle

which demonstrate that the “reality” we see consists of constrained models constructed in the brain. The Necker Cube’s two-dimensional pattern of lines on paper is compatible with two alternative constructions of a three-dimensional cube, and the brain adopts the two models in turn: the alternation is palpable and its frequency can even be measured. The Penrose Triangle’s lines on paper are incompatible with any real-world object.
These illusions tease the brain’s “model-construction software”, thereby revealing its existence. In the same way, the brain constructs in software the useful illusion of personal identity, an ‘I’ apparently residing just behind the eyes, an “agent” taking decisions by free will, a unitary personality, seeking goals and feeling emotions. Which is why AGI is not around the corner. The ineffable aspects of human personality and emotions remain mostly undecipherable by neuroscientists and programming such things is a very, very, long way off, at least 30-40 years. As one presenter noted at a conference:
The mind is an evolved system. As such, it is unclear whether it emerges from a unified principle (a physics-like theory of cognition), or is the result of a complicated assemblage of ad-hoc processes that just happen to work. It’s probably a bit of both. It is going to take a very, very long time to unbox that.
It’s why the Google Brain Team made a switch in meta-learning: teaching machines to learn to solve new problems without human ML expert intervention. But as a member of that Google team noted at DLD Tel Aviv:
There will not be a real AI winter, because AI is making real progress and delivering real value, at scale. But there will be an AGI winter, where AGI is no longer perceived to be around the corner. AGI talk is pure hype, and interest will wane.
As I learned in my neuroscience program, the construction of personhood takes place progressively in early childhood, perhaps by the joining up of previously disparate fragments. Some psychological disorders are interpreted as “split personality”, failure of the fragments to unite. It’s not unreasonable speculation that the progressive growth of consciousness in the infant mirrors a similar progression over the longer timescale of evolution. Does a fish, say, have a rudimentary feeling of conscious personhood, on something like the same level as a human baby?
In a way, it is why Amazon and Facebook and Google have focused on voice. The ability to convey intent and emotions through voice seems like a universal constant that predates language. Ever noticed how the tone you’d use to ask a question, or give an order, is the same in essentially every language?
That’s why the Conference and Workshop on Neural Information Processing Systems is always so illuminating. There’s no practical path from superhuman performance in thousands of narrow vertical tasks executed by AI, ML, NN to the general intelligence and common sense of a toddler. It doesn’t work that way. ML is both overhyped and underrated. People overestimate the intelligence & generalization power of ML systems (ML as a magic wand). But they also underestimate how much can be achieved with relatively crude systems, when applied systematically (think ML as the steam power of our era, not the “electricity” metaphor).
Note: also last year I kept hearing “Deep learning est mort. Vive differentiable programming!” Deep Learning – due for a rebranding. Enter “differentiable programming”. Yeah, differentiable programming is little more than a rebranding of the modern collection of Deep Learning techniques, the same way Deep Learning was a rebranding of the modern incarnations of neural nets with more than two layers. But even “neural networks” is a sad misnomer. They’re neither neural nor even networks. They’re chains of differentiable, parameterized geometric functions, trained with gradient descent (with gradients obtained via the chain rule). In a way “differentiable programming” is a lot better, but to be honest that seems a lot more general than what we do in deep learning. Deep learning is a very, very small subset of what differentiable programming could be. But I think that generality is intentional. As Francis Callot (professor, Graduate School of Decision Sciences, University of Konstanz, who runs a workshop on information processing) noted: “Differentiable programming is an aspirational goal in which the building blocks used in deep learning have been modularized in a way that allows their flexible use in more general programming contexts.
They key? Intelligence is necessarily a part of a broader system — a vision of intelligence as a “brain in jar” that can be made arbitrarily intelligent independently of its situation is silly. A brain is just a piece of biological tissue, there is nothing intrinsically intelligent about it. Beyond your brain, your body and senses — your sensorimotor affordances — are a fundamental part of your mind. Your environment is a fundamental part of your mind. What would happen if we were to put a freshly-created human brain in the body of an octopus, and let it live at the bottom of the ocean? Would it even learn to use its eight-legged body? Would it survive past a few days? We cannot perform this experiment, but we do know that cognitive development in humans and animals is driven by hardcoded, innate dynamics.
Human culture is a fundamental part of your mind. These are, after all, where all of your thoughts come from. You cannot dissociate intelligence from the context in which it expresses itself. I could write about this for hours but I will end it here.
2. CHINA WILL EQUAL – THEN SURPASS – THE U.S. IN ARTIFICIAL INTELLIGENCE

As I wrote last month, the Conference on Neural Information Processing Systems (NIPS) is the largest conference for machine learning and AI. If you must make a choice about attending an AI conference, you go to this one. It is attended by everybody who is anybody in the AI or ML of NN communities.
Heard throughout the event this year: the United States has long led the world in technology. But as artificial intelligence becomes increasingly widespread, U.S. engineers have quickly learned they need to contend with another global powerhouse – China. It is why Amazon, Apple, Google and others have set up AI research centres in China.
I have a long post coming on the many facets of the AI empire in China so I will be brief here. As many attendees at NIPS noted:
- China has been making rapid advances in AI over the past few years
- China lags behind the US when it comes to engineering talent, as well as in the hardware required to build effective “autonomous AI”—robots, self-driving cars, and other physical machines. But in effect, the “US-China AI duopoly is not only inevitable. It has already arrived.
- One major advantage China enjoys over the US, for example, is access to a massive pool of data. China’s enormous population is well-connected—the country is home to 800 million internet users, the majority of whom have access to mobile devices. According to data from Chinese research firm QuestMobile, China has about three times as many active internet-connected devices as the US. The size of available datasets is the most important source of competitive advantage in AI.
- Meanwhile, in the realm of autonomous AI, Chinese manufacturers are deploying robots at a rapid pace. These robots themselves collect data, which, via a virtuous cycle, can be used to further perfect factory automation.
- But data is only one part of the story. In July, not long after Google’s AlphaGo defeated Chinese champion Ke Jie at a series of Go matches, China’s State Council announced the “Next Generation Artificial Intelligence Development Plan.” The directive called on private enterprises and universities to embrace AI, setting 2030 as the year China becomes “the world’s primary AI innovation center.” China’s strong track record of successfully implementing these top-down directives means this one should be taken seriously.
- And the biggie: the leading AI researchers, university departments and research labs are still in the U.S. but China is moving fast and has the financial firepower that the U.S. does not have. Not only do Chinese companies have the advantage of a hyper-competitive market in which the leading players typically compete across a range of applications and use cases (compared with more specialized leaders in the U.S. so AI research and development is diffuse), the Chinese government continues to invest billions in R&D while unstable U.S. visa policies … and big checkbooks in China … have encouraged more academics to return to China after attending universities in the U.S. More importantly, China has a very, very deep awareness of what’s happening in the English-speaking world, but the opposite is not true. The West has very little feedback on what’s happening in China, hence our amazement when they show off incredible stuff in robotics, neural networks, etc.
More to come on this subject.
3. COMPUTATIONAL PROPAGANDA AND THE END OF TRUTH

As I wrote last year when discussing artificial intelligence and the art of photography, we can no longer trust what we see. As a photographer, I have always thought that pretty soon cameras will be able to automatically adjust highlights, shadows, contrast, cast and saturation based on human aesthetic preferences. Controlling light and shadow is the trickiest thing for a photographer. It’s why manual controls are needed for a pro’s unique art. But that change, that shift is happening at a faster pace than even I imagined. And just like the technology for cyber attacks is now “off the shelf” so almost anyone can launch their own attach, the imaging machine learning algorithms are developed using easily accessible materials and open-source code that anyone with a working knowledge of deep learning algorithms could put together to create their own “truth”, their own “reality”.
Most interesting visual tool I saw? Project Poppetron, which allows for someone to take a photo of a person, give them one of any number of stylized faces, and create an animated clip using the type they’ve chosen. These feats are possible because machine learning can now distinguish the parts of the face and the difference between background and foreground, better than previous models. At Cannes Lions it was a big hit.
Oh, yes, the creation of “fake news”. No, fake news is not a new phenomenon but the online digital information ecosystem now has immense technological capability … “computational propaganda devices” in the trade … that has created a particularly fertile ground for sowing misinformation. Yes, I get it. Agenda setting is generally about power, specifically the power of the media to define the significance of information. But technology has stood this concept on its head. The extent to which social media can be easily exploited to manipulate public opinion thanks to the low cost of producing fraudulent websites and high volumes of software-controlled profiles or pages, known as social bots, is astounding. These fake accounts can post content and interact with each other and with legitimate users via social connections, just like real people – at a speed and duration unheard of. And because people tend to trust social contacts they can be manipulated into believing and spreading content produced in this way.
To make matters worse, echo chambers make it easy to tailor misinformation and target those who are most likely to believe it. The Russians are THE pros at this, far better than the alt-right movement. Moreover, amplification of content through social bots overloads our fact-checking capacity due to our finite attention, as well as our tendencies to attend to what appears popular and to trust information in a social setting. Last year I wrote about attempts by AI mavens to combat this assault via large-scale, systematic analysis of the spread of misinformation by social bots via two tools, the Hoaxy platform to track the online spread of claims and the Botometer machine learning algorithm to detect social bots. They detected hundreds of thousands of false and misleading articles spreading through millions of Twitter posts during and following the 2016 U.S. presidential campaign.
NOTE: there are also technologies such as RumorLens, TwitterTrails, FactWatcher and News Tracer. As I learned at the Munich Security Conference, these and similar technologies were used by the intelligence services to track Russian intelligence activities. These “bot-not-bot”classification systems use more than 1,000 statistical features using available meta-data and information extracted from the social interactions and linguistic content generated by accounts. They group their classification features into six main classes. Network features capture various dimensions of information diffusion patterns. It builds networks based on retweets, mentions, and hashtag co-occurrence, and it pulls out their statistical features, such as degree distribution, clustering coefficient, and centrality measures. User features are based on Twitter meta-data and Facebook meta-data related to an account, including language, geographic locations, and account creation time.
At several conferences, I learned about companies that were paid millions of dollars to create armies of Twitter bots and Facebook bots that allowed campaigns, candidates, and supporters to achieve two key things during the 2016 Presidential election: 1) to manufacture consensus and 2) to democratize online propaganda. Social media bots manufactured consensus by artificially amplifying traffic around a political candidate or issue. Armies of bots were built to follow, retweet, or like a candidate’s content make that candidate seem more legitimate, more widely supported, than they actually are. This theoretically has the effect of galvanizing political support where this might not previously have happened. To put it simply: the illusion of online support for a candidate can spur actual support through a bandwagon effect.
I have a detailed post “in progress” to give you the nuts and bolts of how this was done, so let me close this section with two points:
- Technology has allowed us to cease to be passive consumers, like TV viewers or radio listeners or even early internet users. Via platforms that range from Facebook and Instagram to Twitter and Weibo, we are all now information creators, collectors, and distributors. We can create inflammatory photos, inflammatory texts, inflammatory untruths. And of course, those messages that resonate can be endorsed, adapted, and instantly amplified.
- We have no “common truth”, no “shared truth”. We have polarization and different versions of reality. There is, of course, a huge political and cultural cost for all of this “well-MY-media-says…”, what the French writer (and businessman) Jean-Louis Gassée calls “brouet de sorcières dont nous louche off ce qui convient à vos sentiments” (which, roughly translated, means “a witches’ brew from which we ladle off whatever fits our sentiments”). But I must leave that discussion for another day.
As as far as “fixing” Facebook? Not going to happen. Facebook’s fundamental problem is not foreign interference, spam bots, trolls, or fame mongers. It’s the company’s core business model, and abandoning it is not an option. The only way to “fix” Facebook is to utterly rethink its advertising model. It’s this model which has created nearly all the toxic externalities that dear Mark is so “worried about”. It’s the honeypot which drives the economics of spambots and fake news, it’s the at-scale algorithmic enabler which attracts information warriors from competing nation states, and it’s the reason the platform has become a dopamine-driven engagement trap where time is often not well spent. To put it in Clintonese: It’s the advertising model, stupid.
AND JUST A QUICK NOTE ON THE CHANGES FACEBOOK ANNOUNCED THIS PAST WEEK: Facebook said it’s making some far-reaching changes to what you see in your newsfeed. Mark Zuckerberg: “We want to make sure that our products are not just fun, but are good for people.” So now it’s a morality play?! Tell us what’s good for us Facebook … what should we think, feel or do? Yes, Zuckerberg may have realized his platform is not all-encompassing enough to turn humans into Matrix-like pod people (perhaps that’s a job for Facebook’s Oculus VR division). But this move was surely carefully designed, with product managers realizing that users who abandon social media are unlikely to return, while a cut-down dose of its drug might keep feed junkies hanging around longer, searching for that scrolling high. Ask any dealer – cutting the product is a better scenario than having users overdose and turn up dead. In Facebook’s case, “dead,” mercifully, would mean a user who quits the site cold turkey, and sets themselves free of social media. And that’s clearly not a world Zuckerberg wants to live in. More to come in my next post.
4. THE WORLD OF VIRTUAL ASSISTANTS

At the Mobile World Congress last year, the ever-growing “conference in a conference” is the “living cities” demonstration area. Last year it covered an area the size of 3 football pitches. Living cities are what happens when you bring together sensors, actuators and intelligence to start to respond to the needs of citizens. When you go beyond just “smart” to bring some warmth and engagement.
This is certainly happening in the home. Tom Cheesewright (who writes about this and many other high-level tech subjects) summed up last year for me very nicely when he noted exactly where all of these conferences said these high-tech homes are going, using his own as an example:
There’s no real intelligence in my system — it’s entirely driven by events triggering certain messages. But even with this very simple technology, the house can start to engage with my needs and respond to them in a much more human way than it otherwise might. It can know that I usually like a certain temperature. That I like a certain playlist when I’m cooking, or the lights a certain way when watching a film. And it can tell me that it knows, in quite a natural fashion, and offer solutions to me at appropriate moments.
To truly fit my definition of a ‘living’ system, my house would need ‘real’ intelligence: perhaps predicting needs I hadn’t explicitly expressed. And it would need to be able to evolve its behaviours — and even its physical space — to better meet those needs. Sadly, I can’t 3D-print walls yet. But it’s easy to see that technology coming.
The most interesting part of the Consumer Electronics Show in Las Vegas (held every January; my media team is there now) is not the technology on show but the conversations that happen behind closed doors. Last year and this year are no exception. In the world of virtual assistants, Amazon and Google are leading the way on recruiting partners to help them distribute and activate their artificial intelligence platforms. After focusing on “smart home” technology last year, Amazon is now moving on to the car. It has struck deals with Panasonic, one of the largest players in in-car infotainment systems, Chinese electric car start-up Byton and Toyota .. which this year is showing off a futuristic, versatile autonomous vehicle called “e-Palette” … that the ecommerce group plans to use for package deliveries.
Note: Amazon never has its own public presence on the CES show floor. It rents a sizeable private space (12 suites, 6 conference rooms) in Las Vegas’s Venetian hotel for meetings with partners. Google, by contrast, is unmissable to CES attendees: advertising for Assistant appears on giant digital billboards up and down the Las Vegas Strip, its branding is plastered inside and outside the city’s monorail train carriages, and it will for the first time in several years has a yuuuuuuge booth at the convention centre.
5. ALGORITHMS THAT SUMMARIZE LENGTHY TEXT GET BETTER, AS DOES TRANSLATION SOFTWARE

Training software to accurately sum up information in documents could have great impact in many fields, such as medicine, law, and scientific research. And if you are a member of the e-discovery ecosystem, no, you will not see this technology at LegalTech or ILTA. But it is starting to become routine to rely on a machine to analyze and paraphrase articles, research papers, and other text for you. At two computational linguistic events I saw demos by Metamind (recently acquired by Salesforce) and developed by Richard Socher, who is a fairly prominent name in machine learning and natural-language processing. There are others out there, like Narrative Science and Maluuba (acquired last year by Microsoft).
All of these use several machine-learning tricks to produce surprisingly coherent and accurate snippets of text from longer pieces. And while it isn’t yet as good as a person, it hints at how condensing text could eventually become automated. Granted, the software is still a long way from matching a human’s ability to capture the essence of document text, and other summaries it produces are sloppier and less coherent. Indeed, summarizing text perfectly would require genuine intelligence, including commonsense knowledge and a mastery of language.
But parsing language remains one of the grand challenges of artificial intelligence and it’s a challenge with enormous commercial potential. Even limited linguistic intelligence – the ability to parse spoken or written queries, and to respond in more sophisticated and coherent ways – could transform personal computing. Last year our e-discovery review unit participated in a beta test of a system that learns from examples of good summaries, an approach called supervised learning, but also employs a kind of artificial attention to the text it is ingesting and outputting. This helps ensure that it doesn’t produce too many repetitive strands of text, a common problem with summarization algorithms.
The system experiments in order to generate summaries of its own using a process called “reinforcement learning”. Inspired by the way animals seem to learn, this involves providing positive feedback for actions that lead toward a particular objective. Reinforcement learning has been used to train computers to do impressive new things, like playing complex games or controlling robots and at the end of 2016 it seemed to be on everybody’s “breakthrough technologies in 2017” list. Those working on conversational interfaces are increasingly now looking at reinforcement learning as a way to improve their systems.
If you are a lawyer, would you trust a machine to summarize important documents for you? Did you trust predictive coding when it first hit the market? It is a work-in-progess.
In modern translation software, a computer scans many millions of translated texts to learn associations between phrases in different languages. Using these correspondences, it can then piece together translations of new strings of text. The computer doesn’t require any understanding of grammar or meaning; it just regurgitates words in whatever combination it calculates has the highest odds of being accurate. The result lacks the style and nuance of a skilled translator’s work but has considerable utility nonetheless. Although machine-learning algorithms have been around a long time, they require a vast number of examples to work reliably, which only became possible with the explosion of online data. As a Google engineer (he works in Google’s Speech Division) at DLD Tel Aviv:
When you go from 10,000 training examples to 10 billion training examples, it all starts to work. In machine learning, data trumps everything. And this is especially the case with language translation.
Here in Europe our e-discovery review team and our language translation service have been using Bitext (they are based in Madrid), which is a deep linguistic analysis platform, or DLAP. Unlike most next-generation multi-language text processing methods, Bitext has crafted a platform. Based on our analysis plus an analysis done by ASHA, the Bitext system has accuracy in the 90 percent to 95 percent range. Most content processing systems today typically deliver metadata and rich indexing with accuracy in the 70 to 85 percent range. The company’s platform supports more than 50 languages at a lexical level and +20 at a syntactic level and makes the company’s technology available for a wide range of applications including Big Data, Artificial Intelligence, social media analysis, text analytics, etc. It solves many complex language problems and integrates machine learning engines with linguistic features. These include segmentation, tokenization (word segmentation, frequency, and disambiguation, among others.
6. E-DISCOVERY FACES THE DEMON IT KNEW WAS COMING

As I noted above, the truth is on the run. And the e-discovery industry will battle it. Ralph Losey is right. The big problems in e-discovery have been solved, especially the biggest problem of them all, finding the needles of relevance in cosmic-sized haystacks of irrelevant noise. We can go to almost any legal technology vendor and law firm and they will know what is required to do e-discovery correctly. We have the software and attorney methods needed to find the relevant evidence we need, no matter what the volume of information we are dealing with.
But where are we with the new e-discovery demon? How do you discover what is not there but should be there. My e-discovery review team only works in EMEA (Europe, the Middle East and Africa). There, it is the Wild, Wild West. Nobody cares about “meet & confer’, or “proportionality”, or “legal holds”. Even U.S. companies that operate there. My team does “hard discovery” (compliance and corporate internal investigations) and “extreme discovery” (document pulls and forensics in places like Cote D’Ivoire, Iran, Libya, etc.) Last year we did three internal investigations for Fortune 100 companies. Fraud, collusion with competitors, carving up markets, etc. All HIDDEN via intranets, Messenger (the preferred messaging system among corporates these days), and chat bots. Few emails … or very incomplete email threads … because the email threads had been “cleansed”. No existing e-discovery software can find what is not there. Google and several other AI vendors are working to develop solutions to these issues, but nobody in the present e-discovery ecosystem has the capacity … or the budget … to address the issue.
Note: at Slush I met with a company that is developing a novel paradigm to impute missing data that combines a decision tree with an associative neural network. More in a later post.
We sometime stumble upon the “truth” because we often do a full review of 1000s of docs. We build a narrative, then determine where was the answer to the earlier email that begged for a response: where was the bid qualification in a cursory note, where was the collusion hinted in an answer, etc. … in other words what information was missing based on our holistic review of the corpus of data.
AI can now create false audio, false emails, false narratives, and can modify meta-data. I think AI is going to make e-discovery harder and harder, the “truth” far easier to hide.
And a side note to my e-discovery readers: as I wrote earlier in my coverage of the murder of a prominent Malta journalist, the use of e-discovery technology is moving outside its normal “neighborhood” and many e-discovery technology companies are seizing the day. I started a master’s degree program in data journalism … three modules: basic technology and data journalism; Law, Regulation and Institutions; and Specialist Journalism, Investigations and Coding … and we are using ED software. I will have more after the International Journalism Festival in Perugia, Italy.
7. ACROSS THE TECH WORLD, VISUALIZATION BECOMES A POTENT METHODOLGY

In the last few years visualization has emerged as a potent methodology for exploring, explaining, and exhibiting the vast amounts of data, information and knowledge produced and captured every second. In 2017 I attended three conferences that were dedicated solely to data visualisation, and attended several where it was a large component.
Researchers and practitioners in visual design, human-computer interaction, computer science, business and psychology aim to enhance the facilitation of knowledge transfer among various stakeholders, and develop methods for the reduction of information overload and misuse. This is vital in the current knowledge economy, where knowledge has become crucial for gaining competitive edge, especially in public policy, scientific research, technological innovation and decision making processes.
These events are cool because they involve engineers, designers and psychologists. Engineers handle the information technology aspect, designers bring visual communication and representation to the table, and psychologists study how humans learn and interpret visuals. Thus, the collaboration between engineers, designers and psychologists is crucial for making sure that visualization indeed succeeds in enhancing knowledge transfer.
And the questions raised are broad: what is gained and what is lost in the transition from data, through images, to insights? What are we taking for granted in the mechanization of statistical image making? And how can we better structure the roles of machines in the creation of visualization, and humans in its interpretation?
8. COMPUTERS HAVE TURNED GERRYMANDERING INTO A SCIENCE

THIS IS MORE FOR MY U.S. READERS. About as many Democrats live in Wisconsin as Republicans do. But you wouldn’t know it from the Wisconsin State Assembly, where Republicans hold 65 percent of the seats, a bigger majority than Republican legislators enjoy in conservative states like Texas and Kentucky. The United States Supreme Court is trying to understand how that happened. This past fall the justices heard oral arguments in a case called Gill v. Whitford, reviewing a three-judge panel’s determination that Wisconsin’s Republican-drawn district map is so flagrantly gerrymandered that it denies Wisconsinites their full right to vote. A long list of elected officials, representing both parties, filed briefs asking the justices to uphold the panel’s ruling. I was in Washington, D.C. that day and a long-time member of The Posse List (my legal recruitment company) finagled a seat for me.
This isn’t a politics story; it’s a technology story. Gerrymandering used to be an art, but advanced computation has made it a science. Wisconsin’s Republican legislators, after their victory in the census year of 2010, tried out map after map, tweak after tweak. They ran each potential map through computer algorithms that tested its performance in a wide range of political climates. The map they adopted is precisely engineered to assure Republican control in all but the most extreme circumstances. In a gerrymandered map, you concentrate opposing voters in a few districts where you lose big, and win the rest by modest margins. But it’s risky to count on a lot of close wins, which can easily flip to close losses. Justice Sandra Day O’Connor thought this risk meant the Supreme Court didn’t need to step in. In a 1986 case, she wrote that “there is good reason to think political gerrymandering is a self-limiting enterprise” since “an overambitious gerrymander can lead to disaster for the legislative majority.”
Well, back then, she may have been right. But today’s computing power has blown away the self-limiting nature of the enterprise, as it has with so many other limits. There is a technical paper that was introduced into the court record that paints a startling picture of the way the Wisconsin district map protects Republicans from risk. Remember the Volkswagen scandal? Volkswagen installed software in its diesel cars to fool regulators into thinking the engines were meeting emissions standards. The software detected when it was being tested, and only then did it turn on the antipollution system. The Wisconsin district map is a similarly audacious piece of engineering. Fascinating stuff.
9. NOTHING ON THE NET IS NEUTRAL

If Bitcoin seemed to eat the last days of the year as the number one topic in tech and the economy, then net neutrality had to be running a very close second. Several of the tech events I attended in the fall had “net neutrality” as the lead topic.
Me? I am in the camp of John Battelle. What strikes me as interesting about all this is now that net neutrality is no longer government policy, we’re going to get a true test of our much-vaunted free market. Will competition truly blossom? Will, for example, new ISPs spring up that offer “net neutrality as a service” – in opposition to the Comcasts and Verizons of the world, who likely will offer tiered bundles of services favoring their business partners? I have to admit, I find such a scenario unlikely, but to me, the silver lining is that we get to find out. Certainly worth the price of admission for purists. And in the end, perhaps that is the only way that we can truly know whether preserving neutrality is a public good worthy of enshrinement in federal law.
Of course, net neutrality today is utterly conflated with the fact that Google and Facebook have become the two most powerful companies on the Web, and have their own agendas to look after. It’s interesting how muted their support was for neutrality this time around.

As I noted in a longer piece earlier this year from the International Cybersecurity Forum in Lille, France, quantum secure direct communication (commonly known in the science as “QSDC”) is an important quantum communication branch, which realizes the secure information transmission directly without encryption and decryption processes.
Chinese scientists have demonstrated actual quantum secure direct communication — with quantum memory — in several tabletop experiments. So this most recent breakthrough is another large step toward secure quantum communication at meaningful distances. The researchers produced a paper (it is a tough read but skip the math and just scan it) that says that the method could be scaled up to send messages “tens of kilometers.” The U.S. has not achieved anything close to these milestones.
Yet another example of China vaulting ahead in an area where the U.S. was comfortably dominant not long ago. Chief among the reasons for this growing trend is that U.S. funding for basic science is unpredictable at best. Conversely, Chinese investment is strategic, sustained, and stable – particularly in quantum science. Put simply, the U.S. does not appear to be prioritizing investments in quantum sciences at comparable levels to China.
11. ASTRONOMERS ARE USING AI TO STUDY THE VAST UNIVERSE – REALLY, REALLY FAST

In one of my weekend jaunts to the Observatoire de Paris, the largest national research center for astronomy in France and a major study centre for space science in Europe, I attended a workshop on the use of AI in celestial study.
Note: the Observatoire is surpassed in Europe only by the Roque de los Muchachos Observatory in the Canary Islands, Spain. That observatory is located at an altitude of 2,396 metres (7,861 ft), which makes it one of the best locations for optical and infrared astronomy in the Northern Hemisphere. The observatory also holds the world’s largest single aperture optical telescope.
There are new methods that didn’t exist 5 to 10 years ago that either improved speed or accuracy which shows why the number of astronomy papers mentioning machine learning in arxiv.org have increased five-fold over the past five years.
Without getting too geeky, a summary of how they are using AI:
1) To coordinate telescopes. The large telescopes that will survey the sky will be looking for transient events. Some of these events – like gamma ray bursts, which astronomers call “the birth announcements of black holes” – last less than a minute. In that time, they need to be detected, classified into real or bogus events (like an airplane flying past), and the most appropriate telescopes turned on them for further investigation. And we talking about the an order of 50,000 transient events each night and hundreds of telescopes around the world working in concert. It has to be machine to machine.2) To analyze data. Every 30 minutes for two years, NASA’s new Transiting Exoplanet Survey Satellite will send back full frame photos of almost half the sky, giving astronomers some 20 million stars to analyze. We are at the petabyte range of data volume.
3) To mine data. Most astronomy data is thrown away but some can hold deep physical information that we don’t know how to extract.
Most intriguing question: how do you write software to discover things that you don’t know how to describe? There are normal unusual events, but what about the ones we don’t even know about? How do you handle those? More to come on this topic.

Last year when Regina Dugan, the head of Facebook’s secretive hardware lab called Building 8 (and the former head of DARPA, by the way) announced at Facebook’s developer conference that Facebook planned to build a brain computer interface to allow users to send their thoughts directly to the social network without a keyboard intermediary, it had all the Silicon Valley swagger of Facebook circa “move fast and break things.” It came just a few weeks on the heels of Tesla-founder Elon Musk’s announcement that he was forming a new venture, Neuralink, to develop a brain implant capable of telepathy, among other things.”We are going to hack our brain’s operating system!! Humans are the next platform!!” crowed Silicon Valley.
Are we, though? No. It might be because I have just finished the coursework for my neuroscience program. But I am … well … fed up. Yes, agreed. Over the past decade, science has made some notable progress in using technology to defy the limits of the human form, from mind-controlled prosthetic limbs to a growing body of research indicating we may one day be able to slow the process of aging. Our bodies are the next big candidate for technological optimization, so it’s no wonder that tech industry bigwigs have recently begun expressing interest in them. A lot of interest.
But let’s take a look at the most “computational” part of the body, the brain. Our brains do not “store” memories as computers do, simply calling up a desired piece of information from a memory bank. If they did, you’d be able to effortlessly remember what you had for lunch yesterday, or exactly the way your high school boyfriend smiled. Nor do our brains process information like a computer. Our gray matter doesn’t actually have wires that you can simply plug-and-play to overwrite depression a la Eternal Sunshine. The body, too, is more than just a well-oiled piece of machinery. We have yet to identify a single biological mechanism for aging or fitness that any pill or diet can simply “hack.”
Research into some of these things is underway, but so far much of what it has uncovered is that the body and brain are incredibly complex. Scientists do hope, for example, that one day brain computer interfaces might help alleviate severe cases of mental illnesses like depression, and DARPA is currently funding a $65 million research effort aimed at using implanted electrodes to tackle some of the trickiest mental illnesses. After decades of research, it’s still unclear which areas of the brain even make the most sense to target for each illness.
The body is not a computer. It cannot be hacked, rewired, engineered or upgraded like one, and certainly not at the ruthless pace of a Silicon Valley startup. Let’s be clear about something. Human intelligence is 13.8 billion years old since we were made from that Big Bang stardust. Our eukaryotic cells formed 2.7 billion years ago. Yes, mitochondria which powers our brain cells was formed then and mitochondrial DNA is inherited from our mothers. And, yes, computing is traceable to Babbage and Lovelace circa 1840s. But talk to the real AI folks and “computer logic” is traceable to Aristotle circa 384-322 BC – so about 2,300 years. That all means it’s scientifically invalid to suppose the human body and its brain data works like machine logic of {0 or 1, %}.
I blame Claude Shannon. I know, the nerve. The man at the birth of the computer age (the best book to read about him, which came out last summer: A Mind at Play: How Claude Shannon Invented the Information Age). He was that he was writing at the same time that major research was underway at several universities on how the brain worked and Shannon developed the metaphor of “the brain as a processor of information” and other computer terminology to describe the brain. That he wrote at a time propelled by subsequent advances in both computer technology and brain research, a time that saw an ambitious multidisciplinary effort to understand human intelligence, it is probably no surprise that firmly rooted would be the idea that humans are, like computers, information processors. The information processing metaphor of human intelligence would dominate human thinking, both on the street and in the sciences. And, yes: I often fall into the trap of using it, too.
13. BUILT YOURSELF AN ARTIFICIAL PANCREAS — FROM OFF-THE-SHELF PARTS

Dana Lewis from Alabama built herself an artificial pancreas from off-the-shelf parts. Her design is open source, so people with diabetes can hack together solutions more quickly than drug companies. And she got a lot of help from social media.
I know, I know. Alabama’s mostly good for football and barbecue. Dana proves how wrong you can be. She made a detailed presentation at the European Parliament in Brussels, Belgium in May 2017. A University of Alabama graduate, she used social media, computer skills and mail-order parts to invent an artificial pancreas for people with diabetes. Along with co-inventor and husband Scott Leibrand, she’s now giving her discovery away. The device is a runaway success – hundreds of people are using it, including Lewis. And it has brought the young inventor increasing attention, Fast Company putting the 28-year-old Lewis on its 2017 list of America’s 100 “most creative people in business.”
Diabetes is caused when the pancreas fails to make the insulin that helps the body turn glucose from sugar and carbohydrates into energy. Without insulin, sugar builds up in the blood stream. With too much insulin, it can fall to dangerously low levels. For diabetics, staying in the safe center is a constant challenge. You need do make hundreds of decisions a day about things that impact your blood sugar. And it really does impact everybody who cares for a person with diabetes.
At the university, Lewis minored in an honors research program that had her spend two years learning to program computers and two years working on projects that used them. That was where she got her first hands-on experience with coding and she said “what was great about the program is it wasn’t about training you to be a computer scientist. Instead, the goal was teaching foundational skills in computing to use for whatever you decide you’re interested in.
She had a continuous glucose monitor and an insulin pump. But it wasn’t enough. She was afraid at night because she a super-deep sleeper. She would sleep through the alarms on the device that were supposed to wake her up and save her life. She said: “I always thought, if only I could get my data off this thing, then I could use my phone or computer to make louder alarms.” The data Lewis wanted was from the monitor’s checks on her blood sugar level every five minutes. The alarms were to warn her to eat sugar to raise a low glucose level or take insulin to lower a high one.
She turned to social media. She found somebody else who had figured out how to directly communicate with my insulin pump and actually send commands to it. He shared his code. That’s what open source is: free sharing of code. They closed the loop. Result: an artificial pancreas that monitors blood sugar and controls the insulin pump.
It goes on from there. Lewis engaged in a series of open-source collaborations and the sharing of code. You can watch a 2016 clip of her explaining it all by clicking here.
Note: to make and distribute the devise would violate federal regulations, and to become a company would mean dealing with those regulations. But there is no rule about launching a blueprint on the Internet. So that’s what she did: its called Open APS, which stands for open-sourced pancreas system.
14. HOW DO YOU KNOW YOU ARE A SUCCESSFUL CRYPTOCURRENCY MINING COMPANY? WHEN YOU NEED A BOEING 747 TO SHIP YOUR GRAPHIC CARDS

Joo Long, a technology buddy from Zurich, passed this one along during a cryptocurrency workshop last Spring. It seems a cryptocurrency mining company called Genesis Mining is growing so fast that they rent Boeing 747s to ship graphics cards to their Bitcoin mines in Iceland. Crypto miners – in particular those mining ethereum, the second largest cryptocurrency by market valuation behind bitcoin – have been in the crypto equivalent of a gold rush since early this year. They are racing to take advantage of ethereum’s exploding price by adding more processing power to their mines. Some of them are even resorting to leasing Boeing 747s to fly the increasingly scarce graphics processors from AMD and Nvidia directly to their ethereum mines so they can be plugged in to the network as quickly as possible. Joo: “Time is critical, very critical,in mining. They are renting entire airplanes, Boeing 747s, to ship on time. Anything else, like shipping by sea, loses so much opportunity. Up for grabs is a supply of roughly 36,000 units of new ether, the digital token associated with ethereum, per day. At the (then) current prices of around $200 per ether, that translates to $7.2 million worth of ether that miners compete for each day.
15. IT HAD TO HAPPEN: THE PAY-WITH-A-SELFIE PROJECT

Amazon, Apple and Google are all working on “pay-by-selfie” projects. Mobile payment systems are increasingly used to simplify the way in which money transfers and transactions can be performed. I use four mobile payment systems and I think they are brilliant. As I wrote last year after the Mobile World Congress, there are many more such systems to come.
The one that caught my attention was at the annual MIT Media Lab Emerging Tech which was aimed at developing countries. The argument is that to achieve their full potential as economic boosters in developing countries, mobile payment systems need to rely on new metaphors suitable for the business models, lifestyle, and technology availability conditions of the targeted communities.
The Pay-with-a-Group-Selfie (PGS) project noted at MIT, is being funded by the Melinda & Bill Gates Foundation, and it has developed a micro-payment system that supports everyday small transactions by extending the reach of, rather than substituting, existing payment frameworks. PGS is based on a simple gesture and a readily understandable metaphor. The gesture – taking a selfie – has become part of the lifestyle of mobile phone users worldwide, including non-technology-savvy ones. The metaphor likens computing two visual shares of the selfie to ripping a banknote in two, a technique used for decades for delayed payment in cash-only markets. PGS is designed to work with devices with limited computational power and when connectivity is patchy or not always available. Thanks to visual cryptography techniques PGS uses for computing the shares, the original selfie can be recomposed simply by stacking the shares, preserving the analogy with re-joining the two parts of the banknote.
16. THE CONTINUING DEMOCRATIZATION OF TECHNOLOGY:
A USB-POWERED DNA SEQUENCER THE SIZE OF A MARS BAR

The scientist is in Guinea using a genetic sequencer. That fact alone is astonishing: most sequencing machines are much too heavy and delicate to travel as checked baggage in the hold of a commercial airliner. More importantly, this scientists this sequencer – actually one of three – to read the genomes of Ebola viruses from 14 patients in as little as 48 hours after samples were collected. That turnaround has never been available to epidemiologists in the field before, and could help them to trace sources of infection as they try to stamp out the remnants of the epidemic. The European Mobile Laboratory Project, based in Hamburg, Germany, is providing substantial funding.
This is the democratization of sequencing. The unit … called the MinION … is a palm-sized gene sequencer made by UK-based Oxford Nanopore Technologies. The device is portable and cheap. It can read out relatively long stretches of genetic sequence, an ability increasingly in demand for understanding complex regions of genomes. And it plugs into the USB port of a laptop, displaying data on the screen as they are generated, rather than at the end of a run that can take days.
TACO BELL SPENT TEN YEARS TRYING TO GET ROBOTS TO PICK UP CHEESE AND PUT IT ON TORTILLAS

Before I move on to my “Quick Fire Round”, I want to close out this section with a bit from my second favorite event of the year, Cannes Lions in France (the first being the International Journalism Festival (IJF) in Perugia, Italy).
Now, about that cheese. Said the Taco Bell advertising rep I spoke with, having a fabulous taco with melty cheese in every single bite was something Taco Bell started dreaming about 10 years ago. After a decade-long journey of trial and error that dream eventually became the Quesalupa, a taco served in a cheese-stuffed fried shell whose 2016 arrival was heralded by a Super Bowl ad featuring a cackling George Takei. Costing somewhere from $15 million to $20 million, it was Taco Bell’s most expensive ad campaign ever. And it paid off: the company sold out its run of 75 million Quesalupas during the product’s four-month limited release.
Such is the influence cheese wields over the American consumer. Americans eat 35 pounds of cheese per year on average – a record amount, more than double the quantity consumed in 1975. And yet that demand doesn’t come close to meeting U.S. supply: the cheese glut is so massive (1.3 billion pounds in cold storage as of 31 May 2017) that on two separate occasions, in August and October of last year, the federal government announced it would bail out dairy farmers by purchasing $20 million worth of surplus for distribution to food pantries.
Side note from the Taco Bell rep: “here’s a little secret. If you use more cheese, you sell more pizza. In 1995 we worked with Pizza Hut on its Stuffed Crust pizza, which had cheese sticks baked into the edges. The gimmick was introduced with an ad starring a pizza-loving real estate baron named a guy you might know. Donald Trump. By yearend we had increased Pizza Hut’s sales by $300 million, a 7 percent improvement on the previous year’s. We estimated that if every U.S. pizza maker added one extra ounce of cheese per pie, the industry would sell an additional 250 million pounds of cheese annually”
Add to that a global drop in demand for dairy, plus technology that’s making cows more prolific, and you have the lowest milk prices since the Great Recession ended in 2009. Farmers poured out almost 50 million gallons of unsold milk last year—actually poured it out, into holes in the ground—according to U.S. Department of Agriculture data. In an August 2016 letter, the National Milk Producers Federation begged the USDA for a $150 million bailout.
That Taco Bell is developing its cheesiest products ever in the midst of an historic dairy oversupply is no accident. There exists a little-known, government-sponsored marketing group called Dairy Management Inc. (DMI), whose job it is to squeeze as much milk, cheese, butter, and yogurt as it can into food sold both at home and abroad. Until recently, the “Got Milk?” campaign was its highest-impact success story. But for the past eight years, the group has been the hidden hand guiding most of fast food’s dairy hits (“they are the Illuminati of cheese” said my source) including and especially the Quesalupa. In 2017 – EUREKA!! The finished product is mega-cheesy: with an entire ounce in the shell, the Quesalupa has about five times the cheese load of a basic Crunchy Taco. To produce the shells alone, Taco Bell had to buy 4.7 million pounds of cheese.
And demand skyrocketed to Taco Bell had to develop a cheese filling that would stretch like taffy when heated, figure out how to mass-produce it, and then invent proprietary machinery along the way.
Then it gets pretty funny. Or a little crazy. How to mass-produce the shells became a major problem. They hired four PhDs, two whom … wait for it … had doctorates in chemistry in cheese filling, who compared various varieties’ chemical compositions, specifically the interplay between molecules of a protein called casein found in the space around milk fat (“think of casein as dairy glue that, at the right temperature and pH, gives cheese its pull by binding water and fat in a smooth matrix”).
Yes, Americans may buy less dairy from the grocery store than they used to, but they still like to eat it. After McDonald’s switched from using margarine in its restaurants to real butter in September 2015 – a change this advertising company lobbied for – the company said Egg McMuffin sales for the quarter increased by double digits (“our job is getting cheese into foods that never had any, or to increase the cheese content in foods that do have it”)
And those robots? “We helped Taco Bell on the regulation and food promotion front. Then we helped them automate the manual assembly for the Quesalupa 2.0 [just like software!!] and that will open up a whole other level of scale. Those robots can pick up cheese and put it on tortillas at very, very high speeds, almost 20X the pace of a human worker.”
Ah, the advertising biz. And you thought it was just pop up ads.
QUICK FIRE ROUND
When I was at DLD Tel Aviv three years ago I saw a marvelous piece of artificial intelligence being developed for text analysis technology that data mines a database and pulls snippets out of related documents. We use it amongst many of our research tools and research platforms via a business information platform many of you know, Factiva. Factiva aggregates content from both licensed and free resources, and then depending on the what level you want to pay has all types of search and alert functions: it plows through websites, blogs, images, videos, etc. so you have the ability to do a deep dive pretty much into any region of the world or country in the word based on trends, subject matter etc.
Through Factiva (plus one other service) we monitor 780 news/blog source points that are fed into an algorithm developed by my chief technology officer so that, depending on what I’m writing about, and depending on what assignments my staff has, a tsunami of material is compartmentalized and then distributes to the appropriate staff members for further reading and analysis. Laying on top of that structure is a technology we have been asked to test … we are one of 10 entities in beta mode with this technology … that, using several machine-learning tricks, produces surprisingly coherent and accurate snippets of text from longer pieces (I noted the technology above). And while it isn’t yet as good as a person, it hints at how condensing text could eventually become automated.
The following are a few of the items that came my way last year, plus a few items from Tom Whitehall (noted above), and ending with my favorite book reads of the year:
18. In August, Virginia Tech built a fake driverless van — with the driver hidden inside the seat — to see how other drivers would react. Their reaction: “This is one of the strangest things I’ve ever seen.”
19. Enthusiasts are building their own huge batteries for home energy storage from hundreds of salvaged laptop batteries.
20. The National Health Service in the UK uses more than a tenth of the global stock of pagers. I am sure Brexit will solve the “productivity problem.
21. Chinese insurance startup Zhong An has sold one billion policies in its first year.
22. GPS signals are being spoofed in some areas of Moscow: “the fake signal, which seems to centre on the Kremlin, relocates anyone nearby to Vnukovo Airport, 32 km away. The scale of the problem did not become apparent until people began trying to play Pokemon Go.”
23. One Friday in May 2017, Solar panels in the UK generated more energy than all eight of our nuclear power stations
24. Pine nuts are harvested from the ancient forests on the Chinese border with North Korea. Workers use hydrogen balloons to float alongside the trees and collect pine cones. Sometimes, the balloons escape.
25. According to a study of 100 million Facebook posts, the most effective three word phrase to use in a headline is “…will make you …” The most effective use of the phrase was “10+ Of The Happiest Dog Memes Ever That Will Make You Smile From Ear To Ear”, which was shared more than 600,000 times.
26. Uber is the most lossmaking private company in tech history.
27. China opens around 50 high bridges each year. The entire rest of the world opens ten.
28. Amazon Echo can be useful for people suffering from Alzheimers’: “I can ask Alexa anything and I get the answer instantly. And I can ask it what day it is twenty times a day and I will still get the same correct answer.”
29. In the early 1980s AT&T asked McKinsey to estimate how many cell phones would be in use in the world at the turn of the century. They concluded that the total market would be about 900,000 units. This persuaded AT&T to pull out of the market. By 2000, there were 738 million people with cellphone subscriptions.
30. Chinese company Marvoto have developed a personal ultrasound machine (or ‘Smart portable fetus camera’) so expectant mothers can look at their child at any time. It also produces VR images [Sorry. It is in Chinese. A reader from China passed this on to me]
31. Each year, 28 million tonnes of dust (100,000 lorries’ worth) is picked up by wind from the Sahara desert, carried across the Atlantic and dropped on the Amazon basin. Some of the dust, from an ancient lake bed in Chad, is loaded with phosphorus, a crucial nutrient for the trees in the Amazon rainforest.
32. A fifth of all the Google searches handled via the mobile app and Android devices are voice searches.
33. Facebook employs a dozen people to delete abuse and spam from Mark Zuckerberg’s Facebook page.
34. Citizen scientists have discovered a five-planet system orbiting a distant star.
35. For the first time, scientists have identified a complex molecule in a distant part of the solar system. The find brings scientists closer to solving a 30 year old astronomical mystery: why the universe glows.
36. Why 99% of Australia’s Pacific green sea turtles are female.
37. The rush to invent the first breathalyzer for weed.
38. Psychologists and economists have realised that relying on college kids in their experiments gives spurious results because they’re based on Western, educated, industrialised, rich and democratic (WEIRD) societies.
39. Artificial intelligence systems pretending to be female are often subjected to the same sorts of online harassment as women.
40. In Silicon Valley, startups that result in a successful exit have an average founding age of 47 years.
I try to average 3-4 book reads a month. Here are my favorites for the year:

41. Favorite book read in 2017: The Collected Essays of Elizabeth Hardwick
42. Favorite book read in 2017: When I Grow Up I Want to Be a List of Further Possibilities
43. Favorite book read in 2017: World Without Mind
44. Favorite book read in 2017: We Were Eight Years in Power: An American Tragedy
45. Favorite book read in 2017: Grant
46. Favorite book read in 2017: Margherita Sarrocchi’s Letters to Galileo
47. Favorite book read in 2017: One Day We’ll All Be Dead and None of This Will Matter
48. Favorite book read in 2017: Deep Thinking: Where Machine Intelligence Ends and Human Creativity Begins
49. Favorite book read in 2017: A Mind at Play: How Claude Shannon Invented the Information Age
50. Favorite book read in 2017: Where the Animals Go: Tracking Wildlife with Technology in 50 Maps and Graphics
51. Favorite book read in 2017: David Bowie: The Last Interview and Other Conversations
52. Favorite book read in 2017: A Day in the Death of America
* * * * * * * * * * * * * * * * *
GAZING INTO 2018:
BEYOND THE RHETORIC OF ALGORITHMIC SOLUTIONISM
At an ever increasing pace our culture is being steadily absorbed into the discussion of business. There are “metrics” for phenomena that cannot be metrically measured. Numerical values are assigned to things that cannot be captured by numbers. Economic concepts go rampaging through noneconomic realms: economists are our experts on happiness! Where wisdom once was, quantification will now be. Quantification is the most overwhelming influence upon our contemporary understanding … well, certainly American understanding … of everything. It is enabled by the idolatry of data, which has itself been enabled by the almost unimaginable data-generating capabilities of the new technology.
The distinction between knowledge and information is a thing of the past. And in today’s culture, there is no greater disgrace than to be a thing of the past. Beyond its impact upon culture, the new technology penetrates even deeper levels of identity and experience, to cognition and to consciousness. And even as technologism, which is not the same as technology, asserts itself over more and more precincts of human life, so too does scientism, which is not the same as science. As Virginia Eubanks notes in her new book:
The notion that the nonmaterial dimensions of life must be explained in terms of the material dimensions, and that nonscientific understandings must be translated into scientific understandings if they are to qualify as knowledge, is increasingly popular inside and outside the university, where the humanities are disparaged as soft and impractical and insufficiently new. The contrary insistence that the glories of art and thought are not evolutionary adaptations, or that the mind is not the brain, or that love is not just biology’s bait for sex, now amounts to a kind of heresy. So, too, does the view that the strongest defense of the humanities lies not in the appeal to their utility — that literature majors may find good jobs, that theaters may economically revitalize neighborhoods — but rather in the appeal to their defiantly nonutilitarian character, so that individuals can know more than how things work, and develop their powers of discernment and judgment, their competence in matters of truth and goodness and beauty, to equip themselves adequately for the choices and the crucibles of private and public life.
Or Carl Miller in his new book:
No culture is philosophically monolithic, or promotes a single conception of the human. A culture is an internecine contest between alternative conceptions of the human.
And one sees the inherent problems in the “tech of the day” – implementing algorithmic decision-making tools to enable social services or other high stakes government decision-making so to “increase efficiency or reduce the cost to taxpayers”. Which, of course, shall be “implemented ethically”.
Bullshit. As numerous presenters elucidated at the Conference and Workshop on Neural Information Processing Systems (NIPS) … the mega-AI conference I have noted numerous times in my “52 Things I Learned 2017” … the “ethical AI train has left the station”. Noted one presenter:
In AI and ethics we face a similar issue as the age old security dilemma: speed vs security. These things and their commercial application are simply moving too fast. The same for AI. Same old story: new technology arrives on the scene, society is often forced to rethink previously unregulated behavior. This change often occurs after the fact, when we discover something is amiss. The speed at which this tech is rolled out to the public can make it hard for society to keep up. When you’re trying to build as big as possible or as fast as possible, it’s easy for folks who are more skeptical or concerned have issues they’re raising left by the wayside, not out of maliciousness but because, ‘Oh, we have to meet this ship date’.
And we are fighting governments and/or bad actors pushing self-interested agendas against the greater good. There is, in effect, a war going on that is more threatening than nuclear war. Look at the development of AI agents trained on something like OpenAI’s Universe platform, learning to navigate thousands of online web environments .. and then being tuned to press an agenda. This could unleash a locust of intelligent bots and trolls onto the web in a way that could destroy the very notion of public opinion.
As far as AI bias, as Kate Crawford noted [she gave the keynote at NIPS] our current data sets always stand on the shoulders of older classifications. So Imagenet draws from the taxonomy of Wordnet. So if the older classifications are inherently biased, then that affects the current data sets and the biases may compound.
In the U.S., they do not even “get” the real costs, whether we’re talking about judicial decision making (e.g., “risk assessment scoring”) or modeling who is at risk for homelessness. Algorithmic systems don’t simply cost money to implement. They cost money to maintain. They cost money to audit. They cost money to evolve with the domain that they’re designed to serve. They cost money to train their users to use the data responsibly. Above all, they make visible the brutal pain points and root causes in existing systems that require an increase of services. Otherwise, all that these systems are doing is helping divert taxpayer money from direct services, to lining the pockets of for-profit entities under the illusion of helping people. Worse, they’re helping usher in a diversion of liability because time and time again, those in powerful positions blame the algorithms.
Yes, yes, yes. Any social scientist with a heart desperately wants to understand how to relieve inequality and create a more fair and equitable system. So of course there’s a desire to jump in and try to make sense of the data out there to make a difference in people’s lives. But to treat data analysis as a savior to a broken system is woefully naive.
Doing so obfuscates the financial incentives of those who are building these services, the deterministic rhetoric that they use to justify their implementation, the opacity that results from having non-technical actors try to understand technical jiu-jitsu, and the stark reality of how technology is used as a political bludgeoning tool.
The above paragraph is a simplification of the main point in a new book coming out in a few weeks (I was sent an advance copy for review), Virginia Eubanks’ book “Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor”. It shows the true cost of these systems. It is a deeply researched accounting of how algorithmic tools are integrated into services for welfare, homelessness, and child protection. Eubanks goes deep with the people and families who are targets of these systems, telling their stories and experiences in rich detail. Further, drawing on interviews with social services clients and service providers alongside the information provided by technology vendors and government officials, Eubanks offers a clear portrait of just how algorithmic systems actually play out on the ground, despite all of the hope that goes into their implementation.
Eubanks eschews the term “ethnography” because she argues that this book is immersive journalism, not ethnography. Yet, from my perspective as a researcher and a reader, this is the best ethnography I’ve read in years. “Automating Inequality” does exactly what a good ethnography should do – it offers a compelling account of the cultural logics surrounding a particular dynamic, and invites the reader to truly grok what’s at stake through the eyes of a diverse array of relevant people – screwed by the false promises of these technologies. She makes visible the politics and the stakes, the costs and the hope.
And I love the title – a fantastic backronym for AI.
I look forward to seeing many of you on the tech conference circuit. Have a great 2018.

3 Replies to “LONG READ: 52 things I learned at technology conferences in 2017”