
Robots are coming for priests’ jobs, too.
The BlessU-2 droid offers blessings in 5 languages and recites bible verses.
(More at the end of this post)
Herein, Part 1: machine learning/AI and its complexity, and some unseen social consequences
Coming in Part 2: the “new new” thing of neural network chips and ambient computing devices
2 June 2017 (Jerusalem, Israel) – Writing blogs about emerging technology puts you at risk of becoming enamored with buzzwords. Cloud this, big data that. AI is taking over. Machine learning is “the thing”. So, where does this all lead? Is analytics where I should go? Is there a new bigger buzzword around the corner that overtakes all the others?
My belief is that these phenomena are all interwoven and working toward the same enablers: speed and frictionless computing. One phrase repeated at tech conference after tech conference this year: “Speed and frictionless … they are the new IT.”
Frictionless you know, especially as technology removes the friction from payment. Take a cab, for example, and you still have to get out cash or a credit card, register the cost and decide whether to offer a tip; but take an Uber, and the payment slips so imperceptibly out of your bank account that it might never have happened. Contactless cards can be used to make small payments merely by wafting them near a card reader: no need for a signature or a security code. Using a smartphone for contactless payments reduces the friction even further. Cards tend to be kept in a wallet or purse, but your phone is always at hand: it’s like a magic wand you can just wave to pay for stuff. Economists reckon that the shift towards ever-easier payment systems is boosting consumer spending. Businesses are delighted.
Ah, the frictionless enterprise: a business architecture that optimizes the use of connected digital technologies to strip out cost, delay and opacity when harnessing resources and delivering outcomes. Simply put, it erases the barriers that get in the way of getting things done.
Speed? Well, that’s what all these new computing architectures are about, for instance specialized chips optimized for particular jobs … cloud computing, neural-network processing, computer vision and other tasks … and the techniques that exploit the ability to crunch multiple data sets simultaneously.
Much of this I have written about for my e-discovery readers in a three-part series on technology with a focus on technology assisted legal review, the rapid emergence of the cloud, and the onslaught of AI in the legal world. You can read Parts 1 and 2 by clicking here. Part 3 will be out mid-June.
But in this 2-part series I want to focus more on “The Big Picture”, my macro thoughts. Although I will start with just one point on legal technology to lead us into my discussion on machine learning:
1. The JPMorgan legal department has gone gaga over its new artificial intelligence/machine learning “machine”. It can resolve in one second financial arbitrations that normally take some 360,000 hours of work (one year) for the firm’s lawyers. It is called COIN and was originally developed to analyze simple text but then was developed to interpret commercial loan agreements. Based on its initial 4 test runs: it made significantly fewer mistakes than humans.
2. It is what we saw with AlphaGO … developed by Google’s DeepMind unit … the program which, last week, swept its second human Go player in three straight wins. It has now “retired” from gaming and is moving on to greater challenges that include developing advanced general algorithms to tackle complex problems, such as finding new cures for diseases, and inventing revolutionary new materials.
3. More auspicious for the legal industry, DeepMind’s co-founder and co-CEO Demis Hassabis wants computers to be able to read text, images, video and speech and relate them all in ways never contemplated.
4. So a pattern is set: artificial intelligence makes incredible progress in the small things, and then gradually begins to make its way into a growing number of domains.
MACHINE LEARNING: THE “NEW” FUNDAMENTAL COMPUTER SCIENCE CAPABILITY

With the onslaught of artificial intelligence we seem to have launched into a state where we assume that intelligence is somehow the teleological endpoint of evolution – incredibly anthropocentric, and pretty much wrong along every conceivable axis. Intelligence is an evolutionary response to a particular context and set of survival challenges. I am pretty impressed with the development of flight, speed, fertility, or resilience to radiation. No slackers, they.
But it all fits so neatly into the hot topic of the day … whether we are in a “new age”, called the Anthropocene, where the human imprint on the global environment and human life has now become so large and active that it rivals all the great forces of Nature in its impact on the functioning of the Earth system and human development.
The breathtaking advance of scientific discovery and technology has the unknown on the run. And as we are hurled headlong into the frenetic pace of all this AI development we suffer from illusions of understanding, a false sense of comprehension, failing to see the looming chasm between what your brain knows and what your mind is capable of accessing. It’s a problem, of course. Science has spawned a proliferation of technology that has dramatically infiltrated all aspects of modern life. In many ways the world is becoming so dynamic and complex that technological capabilities are overwhelming human capabilities to optimally interact with and leverage those technologies.
I am not adverse to technology. But I am cautious. I keep my “detector” hat on at all times. I belong to the Church of Techticism, Al Sacco’s brilliant new mash-up that is an odd and difficult to pronounce term derived from a combination of the words “skepticism” and “technicism,” which he says is meant to convey a general sense of distrust toward the mainstream technology world and its PR hype machine, with the need also to cast an eye on long-term effects.
Machine learning is happening right now, rolling through the villages, underneath the entire tech industry, what Ben Evans has called “a kind of new fundamental computer science capability”. We certainly see how it has enabled both mixed reality and autonomous cars.
NOTE: the tech industry uses both “augmented reality” and “mixed reality” to mean the same thing. The term AR often gets used for things like Pokemon Go or Snapchat lenses (or even things like those location-based museum audio guides you have used), but what we are talking about is wearing a device over your eyes, that you look through, that places things into the real world. Google Glass was the forerunner. So the term “mixed reality” also floats around the ecosystem although I will revert to AR from time to time in this post. The point is that the device starts to have some awareness of your surroundings, and can place things in your world – as opposed to “virtual reality” which places you into another world, so the headset needs to black out everything else, the headset or glasses sealed around the edges.
We also see machine learning in more prosaic things like relational databases or (in a smaller way) smartphone location. But the point, the aim here is that machine learning is a building block that will be part of everything, making many things better and enabling some new and surprising companies and products. And it’s early days. We are creating machine learning now. It’s still too early to see all of the implications. We are at the very beginning of the S-Curve I discussed in Part 1 of that legal series noted above.
And the reason I mention this is that to try and predict where this will go … well, you will look like an idiot. I was at a McKinsey & Company presentation on the history of the mobile industry and the analyst noted if you went into the “Waaaaaay Back Machine” to 1999 when folks were predicting where a mobile internet might go folks were saying “in 10 years time we might get stock tips, news headlines and the weather” on our phones … no where near capturing the speed or complexity of what has happened since then.
Or Jeff Han’s now famous TED Talk in 2006 where he gave a demo of “a very experimental multitouch interface”. A year later, Apple unveiled the iPhone and the tech industry was reset to zero around multitouch. And the other things Han presented as “long off but possible” are things every $50 phone can do. But the point McKinsey made was the audience … a relatively sophisticated and tech-focused group … expressed gasps and applause. What is banal now was amazing then.
So, yes, we have these hugely important new technologies coming, but which are not quite here yet. And I suspect that changes will have much more to do with consumer behavior, and economic “tipping points” than with the primary, frontier technology being built. Ben Evans of Andreessen Horowitz, one of the venture capital firms in Silicon Valley that has its finger in all these technologies, put it like this:
I do not think many people see the real long-term effects of these technologies, especially mixed reality and machine learning. How much consumer choice will dictate. Let me cite just one thing, AR and the potential change in shopping. What happens to your buying choices when machine learning means having a pair of glasses … and these technologies are in development … that can look at your living room and suggest a lamp based on your taste, and then show that lamp … and other lamp options … so you see exactly what it would look like in situ? And then tells you where to buy it?
ALPHAGO, IN CONTEXT

The version of AlphaGo that just defeated Ke Jie last week has been completely rearchitected from last year’s version which beat Lee Se-dol. DeepMind calls it “AlphaGo Master”. And while while AlphaGo does not introduce fundamental breakthroughs in AI algorithmically, and while it is still an example of narrow AI, AlphaGo does symbolize Alphabet’s AI power: in both the quantity/quality of the talent present in the company, the computational resources at their disposal, and the all in focus on AI from the very top. The problem in following all of this is that most of the coverage has been a mix of popular science + PR so the most common questions I’ve seen were along the lines of “to what extent is AlphaGo a breakthrough?”, “How do researchers in AI see its victories?” and “what implications do the wins have?”. Andrej Karpathy is a Research Scientist at OpenAI, and expert at training Deep Neural Nets on large datasets, and he is working on a series explaining the AI behind AlphaGo. He has serialized some initial thoughts so let me share his initial points with the AI wizards amongst my readers:
AlphaGo is made up of a number of relatively standard techniques: behavior cloning (supervised learning on human demonstration data), reinforcement learning (REINFORCE), value functions, and Monte Carlo Tree Search (MCTS). However, the way these components are combined is novel and not exactly standard. In particular, AlphaGo uses a SL (supervised learning) policy to initialize the learning of an RL (reinforcement learning) policy that gets perfected with self-play, which they then estimate a value function from, which then plugs into MCTS that (somewhat surprisingly) uses the (worse!, but more diverse) SL policy to sample rollouts. In addition, the policy/value nets are deep neural networks, so getting everything to work properly presents its own unique challenges (e.g. value function is trained in a tricky way to prevent overfitting). On all of these aspects, DeepMind has executed very well.
That being said, AlphaGo does not by itself use any fundamental algorithmic breakthroughs in how we approach RL problems.
The key point Andrej makes is: zooming out, it is still the case that AlphaGo is a narrow AI system that can play Go and that’s it. The ATARI-playing agents from DeepMind do not use the approach taken with AlphaGo. The Neural Turing Machine has little to do with AlphaGo. The Google datacenter improvements definitely do not use AlphaGo. The Google Search engine is not going to use AlphaGo. Therefore, AlphaGo does not generalize to any problem outside of Go, but the people and the underlying neural network components do, and do so much more effectively than in the days of old AI where each demonstration needed repositories of specialized, explicit code.
But what AlphaGo has shown is the interplay of two networks: a policy network that selects the next move to play, and a value network that analyzes the probability of winning. The policy network was initially based on millions of historical moves from actual games played by Go professionals. But AlphaGo Master goes much further by searching through the possible moves that could occur if a particular move is played, increasing its understanding of the potential fallout. DeepMind believes that the same principle will apply to science and health care, with deep-learning techniques helping to improve the accuracy and efficiency of everything from protein-folding to radiography. Perhaps less ambitiously but no less important.
Much more to say but let’s move on …
JUST A QUICK PEAK INTO ONE ELEMENT OF SELF-DRIVING CARS AND THEIR COMPLEXITY

The crux of any machine learning approach involves data. You need lots and lots of usable data to be able to “teach” a machine. One of the reasons that machine learning has progressed lately is due to the advent of Big Data, meaning tons of data that can be readily captured, stored, and processed. I want to give you just one example of the complexity.
Many of the self-driving car makers are utilizing machine learning to imbue their AI systems with an ability to drive a car. What kind of data are the developers using to “teach” the automation to drive a car? When I was at the self-driving car technology conference in Germany earlier his year it was explained as follows:
The developers are capturing huge amounts of data that arises while a car is being driven, collecting the data from a myriad of sensors on the car. These sensors include cameras that are capturing images and video, radar devices that capture radar signals, LIDAR devices that capture laser-based distance points data, and the like. All of this data can be fed into a massive dataset, and then crunched and processed by machine learning algorithms. Indeed, Tesla does this data collection over-the-air from their Tesla cars and can enhance their existing driving algorithms by examining the data and using it to learn new aspects about how their Autopilot software can improve as a driver of the car.
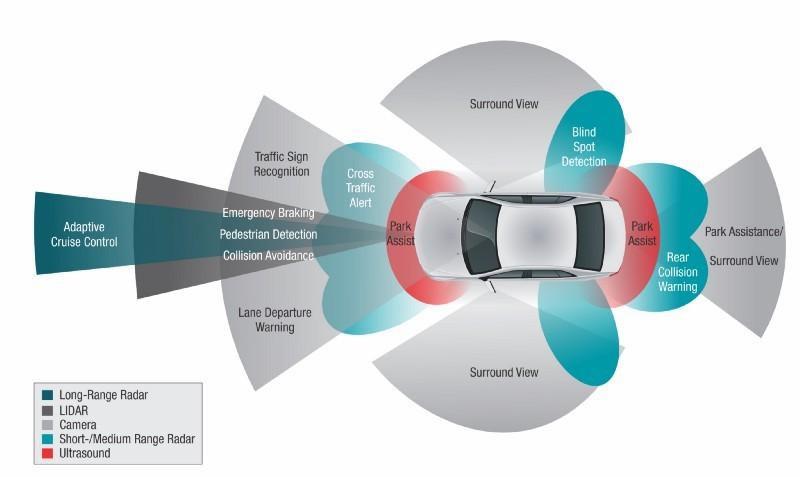
How much data are we talking about? Britt Sekque at Intel (a company that has become quite involved in self-driving car technology) sent me this:
- Radar data: 10 to 100 KB per second
- Camera data: 20 to 40 MB per second
- Sonar data: 10 to 100 KB per second
- GPS: 50 KB per second
- LIDAR: 10 to 70 MB per second
So … if you add all that up, you get about 4,000 GB per day of data, assuming that a car is being driven about 8 hours per day.
NOTE: as a basis for comparison, Google Analytics estimated that the average tech-savvy person uses only about 650 MB per day when you add-up all of the online social media, online video watching, online video chatting, and other such uses on a typical day.
The estimates of the data amounts being collected by self-driving cars varies somewhat by the various analysts and experts that are commenting about the data deluge. For example, it is said that Google Waymo’s self-driving cars are generating about 1 GB every second while on the road, which makes it 60 GB per hour, and thus for 8 hours it would be about 480 GB. Based on how much time the average human driver drives a car annually, it would be around 2 petabytes of data per year if you used the Waymo suggested collection rate of data.
There’s not much point about arguing how much data per se is being collected, and instead we need to focus on the simple and clear cut fact that it is a lot of data. A barrage of data. A torrent of data. And that’s a good thing for this reason – the more data we have, the greater the chances of using it wisely for doing machine learning. Notice that I said we need to use the data wisely. If we just feed all this raw data into just anything that we call “machine learning” the results will not likely be very useful. Keep in mind that machine learning is not magic. It cannot miraculously turn data into supreme knowledge. Lance Elliot, CTO at Techbrium (a company with a brilliant innovation lab and that does a lot of self-driving car analysis) :
The data being fed into machine learning algorithms needs to be pre-processed in various fashions. The machine learning algorithms need to be setup to train on the datasets and adjust their internal parameters correspondingly to what is found. One of the dangers of most machine learning algorithms is that what they have “learned” becomes a hidden morass of internal mathematical aspects. We cannot dig into this and figure out why it knows what it knows. There is no particular logical explanation for what it deems to be “knowledge” about what it is doing.
This is one of the great divides between more conventional AI programming and the purists approach to machine learning. In conventional AI programming, the human developer has used some form of logic and explicit rules to setup the system. For machine learning, it is typically algorithms that merely mathematically adjust based on data patterns, but you cannot in some sense poke into it to find out “why” it believes something to be the case.
Now, Elliot takes us through those crucial distinctions:
Let’s take an example of making a right turn on red. One approach to programing a self-driving car would be to indicate that if it “sees” a red light and if it wants to make a right turn, it can come to a stop at the rightmost lane, verify that there isn’t anyone in the pedestrian walkway, verify that there is no oncoming traffic to block the turn, and then can make the right turn. This is all a logical step-by-step approach. We can use the camera on the self-driving car to detect the red light, we can use the radar to detect if there are any pedestrians in the walkway, and we can use the LIDAR to detect if any cars are oncoming. The sensory devices generate their data, and the AI of the self-driving car fuses the data together, applies the rules it has been programmed with, and then makes the right turn accordingly.
Compare this approach to a machine learning approach. We could collect data involving cars that are making right turns at red lights. We feed that into a machine learning algorithm. It might ultimately identify that the red light is associated with the cars coming to a halt. It might ultimately identify that the cars only move forward to do the right turn when there aren’t any pedestrians in the walkway, etc. This can be accomplished in a supervised manner, wherein the machine learning is guided toward these aspects, or in an unsupervised manner, meaning that it “discovers” these facets without direct guidance.
This is not to suggest that we must choose between using a machine learning approach versus a more conventional AI programming approach. It is not a one-size-fits all kind of circumstance. I am justifying to point out that complex systems such as self-driving cars consist of a mixture of both approaches. Some elements are based on machine learning, while other elements are based on conventional AI programming. They work hand-in-hand. But it is highly complex stuff.
TECHNOLOGICAL CHANGES: THE POSITIVE AND NEGATIVE SOCIAL CONSEQUENCES

The thing about technological innovation … most especially when used to solve social problems, which are often conflated with “consumer problems” … is that the risk is not solely in terms of success or failure of the technology from a commercial standpoint, or a failure to effect the desired change. There might very well be unpredictable deleterious effects that are ignored. We might exclude from consideration any new social and political contexts which may arise from the introduction of technology.
Adrian Bowyer, who is an English engineer and mathematician and inventor of the RepRap Project which is an open-source self-replicating 3D printer, thinks AI/machine learning has taken us down a slippery slope. He recently made a presentation in which he termed AI as an uncontrollable technology. He said:
Inventors have a far greater impact on the world than the actions of any politician. Every technology sits somewhere on a continuum of controllability that can be adumbrated by two of its extremes: nuclear energy and genetic engineering. If I want to build a nuclear power station then I will need a big field to put it in, copious supplies of cooling water and a few billion quid. Such requirements mean that others can exert control over my project. Nuclear energy is highly controllable. If, by contrast, I wanted to genetically engineer night-scented stock to make it glow in the dark so it attracted more pollinators, I could do so in my kitchen with equipment that I could build myself. Genetic engineering is uncontrollable.
AI has given us uncontrollable technologies … starting as an idea in the minds of several people with differing senses of responsibility … so that the responsibility for uncontrollable technologies lies entirely with their inventors. They alone decide whether or not to release a given technology. All other things being equal, an uncontrollable technology will have greater Darwinian fitness than a controllable one when it comes to being reproduced. There is the conundrum.
Ignoring the consequences of technical innovation while implicitly assuming that its effects can only ever be benign can kill our societal structures.
Yes, much of it dazzles. But oh the conflicting societal consequences. I was at an AR demo and wore these AR devices that can map the 3D surfaces of a room … but not “understand” the room. But then the real power of the technology was suggested:
Let’s suppose I meet you at a networking event and I see your LinkedIn profile card over your head, or see a note from Salesforce telling me you’re a key target customer, or a note from Truecaller saying you’re going to try to sell me insurance and to walk away. Or, as that episode on “Black Mirror” suggested, you could just block people. That is, the cluster of image sensors in your “glasses” aren’t just mapping the objects around me but recognising them.
And that is the real augmentation of reality – you’re not just showing things in parallel to the world but as part of it. Your glasses can show you the things that you might look at on a smartphone or a 20 inch screen, but they can also unbundle that screen into the real world, and change it. So, there’s a spectrum – on one hand, you can enrich (or pollute) the entire world by making everything a screen, but on the other, this might let you place the subtlest of cues or changes into the world – not just translate every sign into your own language when you travel, but correct ‘American English’ into English.
NOTE: there is a hilarious Chrome extension that replaces “millennial” with “snake people”. It kept me amused for hours.
And so we get into all kinds of funky stuff. The more you think about AR as placing objects and data into the world around you, the more that this becomes an AI question as much as a physical interface question. What should I see as I walk up to you in particular? LinkedIn or Tinder? When should I see that new message – should it be shown to me now or later? Ben Evans threw out a great scenario:
How about this? Do I stand outside a restaurant and say ‘Hey Foursquare, is this any good?’ or does the device’s OS do that automatically? How is this brokered – by the OS, the services that you’ve added or by a single ‘Google Brain’ in the cloud? Google, Apple, Microsoft and Magic Leap might all have different philosophical attitudes to this, but it seems to me that a lot of it has to be automatic – to be AI – if you want it to work well. If one recalls the Eric Raymond line that a computer should never ask you something that it should be able to work out, then a computer that can see everything you see and know what you’re looking at, and that has the next decade of development of machine learning to build on, ought to remove whole layers of questions that today we assume we have to deal with manually. So, when we went from the windows/keyboard/mouse UI model of desktop computers to the touch and direct interaction of smartphones, a whole layer of questions were removed – the level of abstraction changed. A smartphone doesn’t ask you where to save a photo, or where you are when you order a car, or which email app to use, or (with fingerprint scanners) what your password is – it removes questions (and also choices). AR ought to be another step change in the same direction: it’s about much more than having smartphone apps float in front of you in little square windows. Snapchat doesn’t work like Facebook’s desktop website, and an ambient, intangible, AI-led UI would change everything again.
And there are a myriad of societal issues.
In what will be a bit of a mashup of presentations, chats and conjectures on autonomous cars plus AR devices from sessions at Google Analytics, McKinsey & Company and Andreessen Horowitz, let me throw out a few points:
- All of this technology poses some pretty obvious privacy and security issues. What happens, as the Google Analytics team asked, when autonomous cars are capturing high-definition, 360 degree video all of the time?
- And what happens if everyone is wearing AR glasses as well? Ben Evans at Andreessen Horowitz asked: “Would it even be possible to go on the run?”
- What if you get hacked? If your connected home is hacked you’ll have poltergeists, but if your AR glasses are hacked you’ll probably hallucinate.
- How many people will have one of these AR devices? Is AR going to be an accessory that a subset of mobile phone users have (like, say, smart watches)? Or will every small town in Brazil and Manila have shops selling dozens of different $50 Chinese AR glasses where today they sell Androids?
- Electric and autonomous cars are just beginning – electric is happening now but will take time to grow, and autonomy is 5-10 years away from the first real commercial launches. But each will destabilize the car industry. So … says Andreessen Horowitz … some long term considerations:
- This will totally change what it means to make or own a car, what it means to drive.
- Gasoline is half of global oil demand and car accidents kill 1.25m people year, and each of those could go away. But if autonomy ends accidents, removes parking and transforms what congestion looks like, then we should try to imagine changes to cities on the same scale as those that came with cars themselves.
- How do cities change if some or all of their parking space is now available for new needs, or dumped on the market, or moved to completely different places?
- Where are you willing to live if ‘access to public transport’ is ‘anywhere’ and there are no traffic jams on your commute?
- How willing are people to go from their home in a suburb to dinner or a bar in a city centre on a dark cold wet night if they don’t have to park and an on-demand ride is the cost of a coffee?
- And how does law enforcement change when every passing car is watching everything, recording everything?
And as for AI and machine learning in the home … well. Murray Goulden, a Research Fellow at the School of Computer Science at the University of Nottingham, has been having a doozy of a time chronicling the “smart home” and all the things that can go wrong. He recently catalogued the following via apps in Amazon Echo and Google Home:
- A father finds out his daughter is pregnant after algorithms identify tell-tale patterns in the family’s store card data.
- Police charge suspects in two separate murder cases based on evidence taken from a Fitbit tracker and a home smart water meter.
- A man sues Uber for revealing his affair to his wife.
Such stories have been appearing in ever greater numbers recently, Goulden points out, as the technologies involved become ever more integrated into our lives. They form part of the dreaded Internet of Things, the embedding of sensors and internet connections into the fabric of the world around us. Over the last year, these technologies, led by Amazon’s Alexa and Google’s Home, have begun to make their presence felt in our domestic lives, in the form of smart home devices that allow us to control everything in the house just by speaking.
To Goulden, we might look at stories like those above as isolated technical errors, or fortuitous occurrences serving up justice. But behind them, he sees something much bigger is going on: the development of an entire class of technologies that can remake the fundamentals of our everyday lives.
It is an issue I have noted many time before: these technologies want to be ubiquitous, seamlessly spanning the physical and virtual worlds, and awarding us frictionless control over all of it. The smart home promises a future in which largely hidden tech provides us with services before we’ve even realized we want them, using sensors to understand the world around us and navigate it on our behalf. It’s a promise of near limitless reach, and effortless convenience.
But, says Goulden, these technologies are … and largely unwittingly … attempting to code some of the most basic patterns of our everyday lives, namely how we live alongside those we are most intimate with. As such, their placement in our homes as consumer products constitute a vast social experiment. If the experience of using them is too challenging to our existing orderings, the likelihood is we will simply come to reject them.
COMING IN PART 2

As I noted in a post to clients last week, Apple is developing a dedicated AI chip called the Apple Neural Engine. The iPhone, iPad, Apple Watch, TV, and even the Mac all have a special coprocessor chip for vector processing designed by Apple which allows for stuff like signal processing, image processing, compression, and neural networking. Apple also wrote the low level match code which all of those things need and implemented a boatload of neural network low level math functions.
This is very big stuff with long-range implications across multiple computational domains. And it also highlights the “Big Gorilla in the Room” : ambient computing devices. With a grip on about 70% of the market, Echo has been the leader among these “ambient computing” devices. Amazon’s primary competitor in this space has been Google’s Home device, but more is on the way with the “Invoke” from harman/kardon, running on Microsoft’s Cortana. And now with this week’s announcement that Apple’s new “Siri Speaker will launch end of the year … YIKES! IT’S SHOW TIME!!
As I noted before, in-home devices are a bridge to what computing will ultimately be: always-on, ambient and cognitive.
I had the opportunity to discuss all of this in depth with Zaid Al-Timimi, a major Apple programmer, as well as Roger Attick, an expert on the ecosystem of intelligent machines and fast data. So stay tuned for Part 2 next week.
Oh, my robot priest …
There was an article in The Guardian earlier this week about a robot priest in Wittenberg, Germany. The robot, aptly named BlessU-2, provides blessings in five languages and recite biblical verses, according to the Guardian’s report. It isn’t being implemented as a replacement for priests yet, but in the very town where Martin Luther launched the Protestant Reformation 400 years ago, his mechanical successor is meant to provoke discussion about whether machines have a place within the clergy.