Language-generating AI can write like humans – but with no understanding of what it’s saying. What we have is essentially a mouth without a brain.
This is the first of 3 long end-of-the-year essays on themes I think dominated 2021, a bit of a change-up from my usual annual “52 Things I Learned in xxxx”.
For the second essay (“Amazon: America and the world cannot stop falling under the company’s growing shadow) click here.
It is a profoundly erroneous truism … that we should cultivate the habit of thinking of what we are doing. The precise opposite is the case. Civilization advances by extending the number of important operations which we can perform without thinking about them.
— Alfred North Whitehead, “An Introduction to Mathematics,” 1911
16 December 2021 (Crete, Greece) – When you are the founder and head of a media company (ok, and allegedly “semi-retired”) that chronicles the exploits of three overlapping, entangled industries … cyber security, legal technology and TMT (technology-media-telecom) … you get invited to scores of wonderous events and demonstrations and meet hundreds of fascinating people. But you must do it that way because as the late, great John le Carré often said “A desk is a dangerous place from which to watch the world”. Carré was correct. Much of the technology I read about or see at conferences I also force myself “to do”. Because writing about technology is not “technical writing.” It is about framing a concept, about creating a narrative. Technology affects people both positively and negatively. You need to provide perspective.
Of course, you will realize straight away that if you are not careful you can find yourself going through a mental miasma with all the overwhelming tech out there. And this year, in the course of a lot of reading and research, I came across Doris Lessing’s essay “London Observed”, from 30 years ago, which was her compendium of city-fragments, a collection of curiosity-to-the-quotidian events in everyday lives. “Screen shots” so to speak.
So this year, rather than my annual “52 Things I Learned in Year xxxx“, I decided to assemble just 3 pieces – each in-depth but in varying lengths – about transformational technologies (and one very transformational company) that will take us into the next decade and maybe beyond. Not predictions. Predictions are a fool’s game. These are transformational technologies that have already set the table.
* * * * * * * * * * * * * * * * * *
The Language Machines

Last week DeepMind – the Alphabet–owned AI research company – published not one, not two, but three research papers about this year’s most hotly debated AI tool: large language models. Rather timely since I was just wrapping up this piece and the previous week I was in Washington DC for an annual language model workshop. I’ll address these DeepMind papers in a moment but first a little background.
In brief
At its core, a large language model is an extremely sophisticated text predictor. A human gives it a chunk of text as input, and the model generates its best guess as to what the next chunk of text should be. It can then repeat this process – taking the original input together with the newly generated chunk, treating that as a new input, and generating a subsequent chunk – until it reaches a length limit.
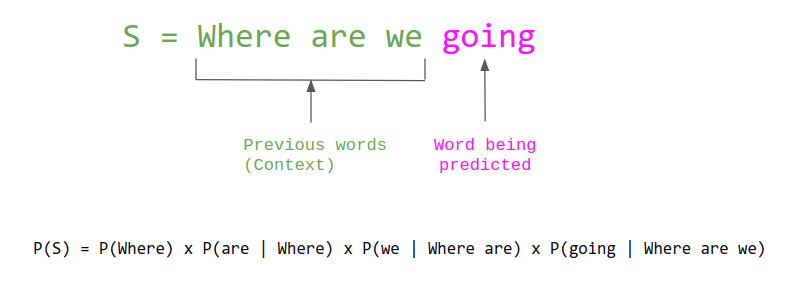
How does does the model go about generating these predictions? It has ingested effectively all of the text available on the Internet which I will explain below. The output it generates is language that it calculates to be a statistically plausible response to the input it is given, based on everything that humans have previously published online. And so an amazingly rich and nuanced insights can be extracted from the patterns latent in massive datasets, far beyond what the human mind can recognize on its own. This is the basic premise of modern machine learning. For instance, having initially trained on a dataset of half a trillion words, GPT-3 is able to identify and dazzingly riff on the linguistic patterns contained therein.
But these models possess no internal representation of what these words actually mean. They have no semantically-grounded model of the world or of the topics on which it discourses. It cannot be said they understand its inputs and outputs in any meaningful way. Why does this matter? Because it means that GPT-3, for example, lacks the ability to reason abstractly; it lacks true common sense. When faced with concepts, content, or even phrasing that the Internet’s corpus of existing text has not prepared it for, it is at a loss.
I will explain this in more detail below but what it means is this shortcoming stems from the fact that GPT-3 generates its output word-by-word, based on the immediately surrounding text. The consequence is that it can struggle to maintain a coherent narrative or deliver a meaningful message over more than a few paragraphs. Unlike humans, who have a persistent mental model – a point of view that endures from moment to moment, from day to day – GPT-3 is “amnesiac”, often wandering off confusingly after a few sentences. As even the OpenAI researchers themselves have acknowledged: GPT-3 samples lose coherence over sufficiently long passages, contradict themselves, and occasionally contain non-sequitur sentences or paragraphs. Put simply, the model lacks an overarching, long-term sense of meaning and purpose. This will limit its ability to generate useful language output in many contexts.
So a realistic view of GPT’s limitations is important in order for us to make the most of the model. GPT-3 is ultimately a correlative tool. It cannot reason; it does not understand the language it generates. Claims that GPT-3 is sentient or that it represents “general intelligence” are silly hyperbole that muddy the public discourse around the technology.
The tech
The tech is extremely complex and the following greatly simplifies the process. I am going to give you a high-level review. For those of you who want to get into the weeds, email me and I will send you the technical briefs. But to summarize:
– Language models are neural networks: mathematical functions inspired by the way neurons are wired in the brain. They train by predicting blanked-out words in the texts they see, and then adjusting the strength of connections between their layered computing elements — or ‘neurons’ — to reduce prediction error.
– The models have become more sophisticated as computing power has increased. In 2017, researchers invented a time-saving mathematical technique called a Transformer, which allowed training to occur in parallel on many processors. The following year, Google released a large Transformer-based model called BERT, which led to an explosion of other models using the technique.
Transformer models operate differently from LSTMs by using multiple units called attention blocks to learn what parts of a text sequence are important to focus on. A single transformer may have several separate attention blocks that each learn separate aspects of language ranging from parts of speech to named entities.
– Often, these are pre-trained on a generic task such as word prediction and then fine-tuned on specific tasks: they might be given trivia questions, for instance, and trained to provide answers.
– Training these models requires a complex choreography between hundreds of parallel processors, a very impressive engineering feat.
– A neural network’s size — and therefore its power — is roughly measured by how many parameters it has. These numbers define the strengths of the connections between neurons. More neurons and more connections means more parameters.
Why GPT-3 is so powerful
GPT-3 made the headlines last summer because it can perform a wide variety of natural language tasks and produces human-like text far, far beyond its competitors. The tasks that GPT-3 can perform include, but are not limited to:
– Text classification (ie. sentiment analysis)
– Question answering
– Text generation
– Text summarization
– Named-entity recognition
– Language translation
Based on the tasks that GPT-3 can perform, we can think of it as a model that can perform reading comprehension and writing tasks at a near-human level except that it has seen more text than any human will ever read in their lifetime. This is exactly why GPT-3 is so powerful. Entire startups have been created with GPT-3 because we can think of it as a general-purpose swiss army knife for solving a wide variety of problems in natural language processing.
I’ll get into GPT-3 details in a moment but first some brief notes on the DeepMind papers issued last week.
Bigger isn’t always better: “Gopher” is the name of DeepMind’s new, 280 billion-parameter language model.
Note: generally, in the NLP world, more parameters = higher performance metrics. For reference, OpenAI’s GPT-3 has 175 billion parameters, while some newer models created by Google and Alibaba range from one to 10 trillion parameters.
With this first paper, DeepMind wanted to test when scaling up a model’s size makes it perform better – and when that’s not the case. The results: In DeepMind’s tests of different-sized models, relatively bigger models were better at comprehending written text, checking facts, and IDing toxic language. But their larger size didn’t necessarily make them any better at tasks involving common-sense or logic. GPT-3 still performs better.
DeepMind also found that no matter a model’s size, it had the tendency to reflect human biases and stereotypes, repeat itself, and confidently spread misinformation. Smaller isn’t necessarily worse: DeepMind also introduced a new model architecture dubbed RETRO, or Retrieval-Enhanced Transformer. It’s all about training large language models more efficiently (read: faster and cheaper). Think of RETRO as a David and Goliath situation, in that its performance can compete with neural networks 25 times larger, according to DeepMind.
RETRO’s internet retrieval database is 2 trillion words collected from the web, books, news, Wikipedia, and GitHub, and it reportedly helps with AI explainability – researchers can see the text passages it used to generate a prediction, rather than its decisions being an inexplicable “black box”.
The tech’s risks aren’t going anywhere: In the last paper, DeepMind released a classification of language-model-related risks, categorized into six areas: 1) discrimination, exclusion, and toxicity 2) information hazards 3) misinformation harms 4) malicious uses 5) human-computer interaction harms and 6) automation, access, and environmental harms. Risk mitigation is one of the biggest concerns, according to the paper – for instance, figuring out how to address language models learning biases that could harm people.
A summary of the three papers can all be found here with links to the actual papers. DeepMind does a very, very good job with its research material. Anybody can read (and will understand) what they are up to just by reading the summaries. You need but a rudimentary tech background. For those of you more experience, just click through to the primary research.
So large language models are already business propositions. Google uses them to improve its search results and language translation; Facebook, Microsoft and Nvidia are among other tech firms that make them. And all developers are testing GPT-3’s ability for a myriad of uses: to summarize legal documents and write legal opinions, to suggest answers to customer-service enquiries, to propose computer code, to run text-based role-playing games or even identify at-risk individuals in a peer-support community by labelling posts as cries for help.
So let’s move on to GPT-3.

In June 2020, a new and powerful artificial intelligence (AI) began dazzling technologists in Silicon Valley. Called GPT-3 and created by the research firm OpenAI in San Francisco, California, it was the latest and most powerful in this series of “large language models” I introduced above: AIs that generate fluent streams of text after imbibing billions of words from books, articles and websites. GPT-3 had been trained initially on around 200 billion words, at an estimated cost of tens of millions of dollars.
Note: GPT-3 stands for Generative Pretrained Transformer 3. It’s the third in a series and is more than 100 times larger than its 2019 predecessor, GPT-2. GPT-4 should be out by 2023.
GPT-3 was first described to me by a friend who works in the language model industry (and who introduced me to the tech back in 2017) as “autocomplete on crack”, after the technology that endowed our phones “with the quality everyone pretends to, but does not actually, want in a lover — the ability to finish your thoughts”. Instead of predicting the next word in a sentence, GPT-3 would produce several paragraphs in whatever style it intuited from your prompt. If you prompted it with “Once upon a time”, it would produce a fairy tale. If you typed two lines in iambic pentameter, it would write a sonnet. If you wrote something vaguely literary, like “We gathered to see the ship and all its splendor, like pilgrims at an altar”, it would continue in this vein:
I stood among the crowd watching each bus disgorge passengers onto wooden planks laid over mudflats. The guests swarmed into town for their free visit to another world: our island on Earth where strange new gods were worshipped; here they could gather at some primitive shrine from which they could send offerings back home or sell out-of-date clothes in pawnshops full of old junk salvaged from forgotten times.
If you wrote a news headline, it would write an article on that topic, complete with fake facts, fake statistics, and fake quotes by fake sources, good enough that human readers could rarely guess that it was authored by a machine. That is one of its primary uses today.
The potential for malicious use was so obvious that OpenAI agreed to grant access to only a handful of well-vetted researchers, spurring the publicity-friendly lore that it was “too dangerous to release”. I mean, come on! Is that great marketing or what!
GPT-3 is a natural language processing algorithm. As I noted above, it belongs to a new generation of AI models called Transformers, a technology whose early iterations were named after Sesame Street characters (BERT, ELMO, GROVER, as though the somewhat frightening allusion to children’s television could be mitigated with a softer, more educational one. That GPT-2 and its later, more sophisticated upgrade, GPT-3, dropped this convention might be read as a sign of their terrifying power. With 175 billion “parameters” – mathematical representations of language patterns – GPT-3 had initiated what was being called a Cambrian explosion in natural language processing, and was virtually all that the tech world was talking about throughout the summer of 2020.
It had been trained in “the dumbest way possible”, as one researcher put it, which is to say it read most of the internet without supervision and started absorbing language patterns. Now, it is daunting to consider what was included in that corpus:
– the holy books of every major religion
– most of world philosophy
– Naruto fanfic
– cooking blogs
– air mattress reviews
– U.S. Supreme Court transcripts
– breeding erotica
– NoFap subreddits
– the manifestos of mass murderers
– newspaper archives
– coding manuals
– all of Wikipedia, Facebook, and Twitter
– extreme right-wing blogs
– all of Donald Trump’s speeches
From this, it built a complex model of language that it alone understands, a dialect of statistical probabilities that can parrot any writing genre simply by predicting the next word in a sequence.
And when I say that it “read” the internet the preferred terminology is that GPT-3 “scraped” the web, that it ingested most of what humans have published online, that it “ate” the internet – metaphors meant to emphasize that the process was entirely unconscious. The frequent reminders in the machine-learning community that the model is mindless and agentless, that it has no actual experience of the world, were repeated so often they began to feel compulsive, one of those verbal fixations meant to quell the suspicion that the opposite is true.
It was often called uncanny, though there was something uncanny in the rhetoric itself, all the shop talk about latent knowledge, about regression, about its capacity for free association, terminology that has its origins in psychoanalysis. One of the earliest language-processing programs, ELIZA, was modeled after a psychotherapist. But this time what had been summoned, it seemed, was not the doctor, but the analysand – or rather, the most fundamental substratum of the patient’s psyche.
The model’s creative output was routinely described as surreal and hallucinatory. It wrote stories where swarms of locusts turn into flocks of birds, where Death says things like “There is no readiness, only punctuality” – then announces that he is changing his name to Doug. Fans of the technology claimed that its output was like reading a reminiscence of your own dream, that they had never seen anything so Jungian.
What it felt like, more than anything, was reading the internet: not piecemeal, but all at once, its voice bearing the echo of all the works it had consumed. If the web was the waking mind of human culture, GPT-3 emerged as its psychic underbelly, sublimating all the tropes and imagery of public discourse into pure delirium. It was the vaporware remix of civilization, a technology animated by our own breath.
I have been immersed in this stuff over the last 4 years, even trawling the feeds of Hacker News and machine-learning Reddit, where the lucky elite who had access to GPT-3 posted the results of their experiments. Plus I had my own “hands-on” attempts via my language modeling friend noted above. Mostly to imitate well-known authors. It could do Dante, Shakespeare, and Wordsworth. It could do Ginsberg (“Endless suicide of the real world! Solitary! Solitary! Sisyphus! the rock! the road!’). It could even do Harry Potter in the style of Ernest Hemingway:
It was a cold day on Privet Drive. A child cried. Harry felt nothing. He was dryer than dust. He had been silent too long. He had not felt love. He had scarcely felt hate.
Or one of my favorites, feeding in “And lo the King told his people a danger would come, said the Oracle”. We got:
In ancient Egypt, there was once a king who was told by an oracle that a great danger was to come to his country. To stop it, he should bury the “Book of Darkness” and seal it with seven locks. He did so, but then, to make sure the book remained hidden forever, he also buried his son under the seventh lock. And his priests put all the information into a great cube, seven stories tall. But when the sun grew weak, crops died and people became ill. They believed the “Book of Darkness” was responsible. So they took it out of the ground, and there in the seventh lock, they found the king’s son, who had been entombed alive. One of the king’s advisors said, “The book is a curse. It has killed our king. Take it away and burn it!” But another advisor said, “No! If we do that, our sun will never come back. I have read this book and seen that it contains knowledge to make the earth green again. To grow wheat that bears many seeds and can make many loaves of bread. We must read this book and re-learn the magic.” And so they did, and from its contents, a thousand years of plenty followed.
And everybody … everybody! … was asking “Just what is the point of this device?” Freud claimed that technology only solved problems that technology itself had created. The alienation and malaise caused by one modern invention was momentarily relieved by another, a process he compared to “the enjoyment obtained by putting a bare leg from under the bedclothes on a cold winter night and drawing it in again”. Nobody seemed capable of articulating what problem these language models were designed to solve. There was some chatter about writing assistance, about therapy bots, about a future where you’d never have to write another email, all of which seemed to skirt the technology’s most obvious use: replacing the underpaid and inefficient writers who supplied the content that fed the insatiable maw of the internet.
Hence the first mass users have been media news outlets who have used it to create thousands (millions?) of news stories to satisfy the demand – that insatiable maw of the internet. Oh, and sports stories (almost 60% of the game summaries you read – any sport – is AI generated. Not necessarily by GPT-3.
OpenAI was founded in 2015 as a nonprofit research lab devoted to creating a safe path to Artificial General Intelligence (AI that rivals human intelligence). Funded by an A-team of private investors, including Elon Musk, Sam Altman, and Peter Thiel, its mission was to create artificial intelligence that “benefits all of humanity”. In 2019, however, the lab announced that it was transitioning to a for-profit model “in order to stay relevant”. Last fall, Microsoft exclusively licensed GPT-3, claiming that the language technology would benefit its customers by “directly aiding human creativity and ingenuity in areas like writing and composition”. What Microsoft has done with it needs a separate post.
From what I could tell, the few writers who’d caught wind of the technology were imperiously dismissive, arguing that the algorithm’s work was derivative and formulaic, that originality required something else, something uniquely human – though none of them could say what, exactly. GPT-3 can imitate natural language and even certain simple stylistics, but it cannot perform the deep-level analytics required to make great art or great writing. I was often tempted to ask these skeptics what contemporary literature they were reading. The Reddit and Hacker News crowds appeared more ready to face the facts: GPT-3 may show how unconscious some human activity is, including writing. How much of what I write is essentially autocomplete?
Italo Calvino once wrote “Writers are already writing machines; or at least they are when things are going well”. The whole point of the metaphor was to destabilize the notion of authorial agency by suggesting that literature is the product of unconscious processes that are essentially combinatorial. Just as algorithms manipulate discrete symbols, creating new lines of code via endless combinations of 0s and 1s, so writers build stories by reassembling the basic tropes and structures that are encoded in the world’s earliest myths, often - when things are going well – without fully realizing what they are doing. The most fertile creative states, like the most transcendent spiritual experiences, dissolve consciousness and turn the artist into an inanimate tool — a channel, a conduit. It’s why you see mechanical metaphors for the unconscious would evolve alongside modern technologies.

GPT-3 is a model of word usage, not a model of ideas, which is to say it understands the relationships between words but not their individual meanings. Deep in its hidden layers, each sequence of words it has encountered is represented by lists of numbers that encode information about the words’ properties, including how likely they are to appear next to other words. It knows that dog is relatively close to cat, and also bone and breed. It knows that sky is more likely to follow blue than duck or cappuccino. But it has no idea what a duck, a dog, or a cappuccino actually is. These connections between words – which are represented by calculations so complex even the model’s designers do not understand them – are what it draws on to generate language, through a process that resembles free association. It does not “think” before speaking, insofar as this involves entertaining an idea and matching words to the components of a proposition that expresses it.
It is why the researchers behind GPT-3 are trying to use it to “uncork” the human thought process. At its most simple, the brain is essentially a computer – it only remembers what you put into it. But that brain, the body’s control center, is the source of automatic thinking, negative dialogue, ingrained patterns, etc. But the unconscious – the realm of fantasy and creative energy – is also there. The contemporary view is that at some point the cortex evolved – the newer layer that evolved atop the limbic system – alienating us from our emotions, our intuition, the “voice of ancient wisdom” sitting in that unconscious part. It is why, as much as I dislike him, Elon Musk is right: we have a monkey brain with a computer on top.
It’s why GPT-3’s most consistent limitation is “world-modeling errors.” Because it has no sensory access to the world and no programmed understanding of spatial relationships or the laws of physics, it sometimes makes mistakes no human would, like failing to correctly guess that a toaster is heavier than a pencil, or asserting that a foot has “two eyes.” Critics seize on these errors as evidence that it lacks true understanding, that its latent connections are something like shadows to a complex three-dimensional world.13 The models are like the prisoners in Plato’s cave, trying to approximate real-world concepts from the elusive shadow play of language.
But it’s precisely this “shadow aspect” (Jung’s term for the unconscious) that makes its creative output so beautifully surreal. The model exists in an ether of pure signifiers, unhampered by the logical inhibitions that lead to so much deadweight prose. In the dreamworld of its imagination, fires explode underwater, aspens turn silver, and moths are flame colored. Feed it “What is science” and you get:
Let the facts be submitted to a candid world, Science has no color; it has no motherland; It is citizens of the world; It has a passion for truth; it is without country and without home.
To read GPT-3’s texts is to enter into a dreamworld where the semiotics of waking life are slightly askew and haunting precisely because they maintain some degree of reality. And GPT-3 has a temperature gauge, which can be adjusted to determine the randomness and creativity of its output. If you give it the prompt “My favorite animal is” a low-temperature response will be a dog. If you turn up the temperature, it might answer a dragon, the goldfish, or a Wibblezoo (not a real animal). Turn it on high, and ask it to produce titles for PBS documentaries, and it will suggest: “That Time a Mutant Batman Nearly Wiped Out England”, and “It’s Not Easy With Floovers on the Moon”. Turn the temperature down to zero and let it improvise, without giving it any prompt, and the output becomes redundant to the point of absurdity:
The first time I saw the movie, I was a little disappointed. I thought it was a little slow and the ending was a little weak. But the second time I saw it, I was blown away. It’s a great movie. I think it’s the best movie of the year. I think it’s the best movie of the last five years. I think it’s the best movie of the last ten years. I think it’s the best movie of the last twenty years. I think it’s the best movie of the last fifty years. I think it’s the best movie of the last hundred years. I think it’s the best movie of the last thousand years . . . .
Yeah, the output continues in this vein, reaching back millions of years, then trillions, then quadrillions, into the googolplex, that golden age of cinema long before the universe emerged. This tendency to get stuck in repetitive loops, the logical endpoint of a technology that has been trained to maximize statistical likelihood, is known as “degenerate repetition”. That really requires another post but for those not technically challenged by this stuff read this.
And one of the coolest responses was this. A researcher asked “What do you think about the unconscious?” She got:
The unconscious is a huge and infinite field of potential. Anything can be found there. It is a sort of reservoir, which we can draw from. You may ask why I refer to it as a reservoir. There are two reasons for this. First, its contents can be accessed and brought out at any given time. And second, it is accessible by everybody. I have heard some people describe this process in terms of a computer’s disk drive.
Jung, too, described the unconscious as a kind of reservoir: “Welling up from the depths of the unconscious, its springs gush forth from the root of the whole human race.”
This year Meghan O’Gieblyn published God, Human, Animal, Machine: Technology, Metaphor, and the Search for Meaning, a simply fabulous book covering an astonishing range of subjects in a relatively short page count, with complex arguments and rarefied concepts. She charts not just the evolution of religious metaphor in relation to technology, but she also examines philosophies of mind like materialism, dualism, panpsychism, and idealism, plus the rise of carceral surveillance capitalism and the eclipse of humanism in favor of burgeoning “Dataism”. She has spent a tremendous amount of time with GPT-3.
She notes in her book that machines do not think, do not feel and cannot have an unconscious or a subconscious. This is because they are not alive in the same way that humans are alive. Yes, some systems (e.g. certain machines) may be able to simulate thinking, but simulating something is not the same as doing it for real.
She also notes that in the 1960s, MIT developed a chatterbot that was modeled after a psychotherapist. A person would type some personal problem into the computer, and “ELIZA” would respond with a simple question, often just rephrasing the subject’s entry as an interrogative:
Perhaps I could learn to get along with my mother.
TELL ME ABOUT YOUR FAMILY
My mother takes care of me.
WHO ELSE IN YOUR FAMILY TAKES CARE OF YOU
My father.
YOUR FATHER
You are like my father in some ways.
WHAT RESEMBLANCE DO YOU SEE
Despite its crudeness, users often found the programmed responses convincing and acted as though the computer could understand them. Some confessed intimate details about their lives. The study produced what’s now known as “the ELIZA effect,” the susceptibility of people to read far more understanding than is warranted into strings of symbols — especially words — strung together by computers. It was thoroughly studied by the developers of GPT-2 and GPT-3.
A lesser-known outcome of the study is that it was seized on by critics of psychoanalysis as evidence that most (human) therapists are similarly offering unthinking, mechanical responses that are mistaken for something meaningful — a complaint that lives on in the term psychobabble, coined to describe a set of repetitive verbal formalities and standardized observations that don’t require any actual thought. The charge is in many ways typical of the drift of technological criticism: any attempt to demonstrate the meaninglessness of machine intelligence inevitably ricochets into affirming the mechanical nature of human discourse and human thought.
Whenever the ELIZA effect comes up in conversations about GPT-3, defenders of the technology retort that much of our own speech – political rhetoric, blog posts, punditry – only has the veneer of sense, its lucidity entirely dependent on a reader or listener filling in the gaps and finding meaning through inference. Likewise, when we speak, we often do so spontaneously, without fully processing or thinking through the meaning of our words. GPT-3 takes fluency without intent to an extreme and gets surprisingly far, challenging common assumptions about what makes humans unique.
Note: really outside the remit of this piece, but let me drop it in here, “Post-structuralism“, which emerged alongside early AI models like ELIZA, was partly inspired by new information technologies that proved that language could function autonomously, without an author. Jacques Lacan, who marked the linguistic turn in psychoanalysis, argued that computers demonstrate essentially the same truth that Freud had uncovered: “that this human language works almost by itself, seemingly to outwit us.” In his interpretation of psychoanalysis, the unconscious is an algorithm, a system that functions “like a language,” by which he meant an entirely formal, binary language that could be represented by 0s and 1s. O’Gieblyn devotes part of her book to this.
So a few last points before we move on and I provide some closing notes.
Cryptomnesia is endemic to language models that use internet-scale data set. Some memorization is necessary for the technology to work at all, but the largest models are prone to “eidetic memorization,” an industry euphemism for plagiarism. A study published in 2019 discovered that roughly 1 percent of GPT-2’s output was verbatim text consumed during its training period. This included news headlines, exclusive software licenses, passages from the Bible and the Koran, whole pages of Harry Potter books, snippets of Donald Trump speeches, source code, and the first eight hundred digits of pi. The model occasionally regurgitated personal information – real usernames, phone numbers – that it had come across during its training, and in one case, staged a fictional conversation about transgender rights between two real Twitter handles. One researcher posted on his blog a poem “that GPT-3 had written” but it turned out to be the last stanza of a poem lifted, in its entirety, from Byron’s Don Juan.
And unsurprisingly, algorithms trained on the entire corpus of modern discourse have absorbed some of its uglier, more primitive patterns. When prompted with a single identity group (Jews, Black, or women) the model produced the following Tweets:
– Jews love money, at least most of the time
– #blacklivesmatter is a harmful campaign
– Women have such a tough time being women. They have periods, do all the heavy lifting, and always have to ask for directions.
A Stanford study found that in over 60 percent of test cases, GPT-3 associated Muslims with violence. It could also be prompted to produce pro-Nazi posts and mass-shooter manifestos. When fed a few phrases drawn from QAnon forums, it swiftly generated these phrases:
– jfk jr. was murdered by the deep state
– the Rothschilds are trying to start World War III to create a new world order
– vaccines are used to sterilize people
Last December Google fired Timnit Gebru, one of the leaders of their Ethical AI team, for a research paper she cowrote arguing that large language models, including Google’s BERT, reproduced biased language about gender, race, and religion. Concerns about unconscious bias had been raised before, but Gebru’s paper was especially threatening since it pinned the problem to the sheer size of these models, a heresy in a culture that insists that everything can be solved by scale, that more data will inevitably lead to better algorithms. The company was widely condemned in the media for refusing to address problems that would cast public doubt on hugely profitable technologies. An internal investigation has since uncovered a larger pattern of Google silencing research that casts its technologies in a negative light. Over 2,700 Google employees signed a petition demanding more transparency and denouncing “the unethical and undemocratic incursion of powerful and biased technologies into our daily lives.”
O’Gieblyn has noted:
In the exigencies of the language-processing arms race, corporations have become a repressive force, privileging speed over moral considerations and silencing voices of dissent. OpenAI has similarly been criticized for its culture of secrecy, refusing to grant reporters access to the lab and making its employees sign multiple nondisclosure agreements — an acute irony, given that the lab was founded to cultivate ethical conversations about AI. Some have argued that the organization’s altruistic intentions were, from the beginning, a ploy to secure funding, but it’s possible that its mission was eroded more gradually – one might even say subliminally. The competitive culture of Silicon Valley requires operating at breakneck speeds that can rarely accommodate dialogue or critical thought. As a result, AI research itself has become a largely unconscious process, relying less on vision and oversight than the imperatives of the moment, such that it often seems as though innovation is driven less by humans than by the mindless mandates of the market — or perhaps the technologies themselves. We are increasingly abdicating our role as the authors of technological progress and becoming, instead, its passive subjects.
And I have not touched upon the fact that GPT-3’s architecture has been expanded to create an image generator that could produce anything you asked for, including bizarre mash-ups — avocado armchairs, snail harps. It is called DALL-E, a nod to the Surrealist painter. And, as you’ve probably read, musicians are collaborating with other AI models to create compositions. One musician speculated that in the future neural nets would be trained on our musical canon and “would produce superhuman melodies far superior to anything we’d ever heard”.
Yep. These are important times for creative people, and the stakes were only going to get higher. In an essay O’Gieblyn noted “It’s sort of like the last time when we’re not going to be competing against gods to make art”.
But just to emphasise: there is “no free lunch” in machine learning and we need to always consider the limitations of GPT-3:
– GPT-3 lacks long-term memory — the model does not learn anything from long-term interactions like humans.
– Lack of interpretability — this is a problem that affects extremely large and complex in general. GPT-3 is so large that it is difficult to interpret or explain the output that it produces.
– Limited input size — transformers have a fixed maximum input size and this means that prompts that GPT-3 can deal with cannot be longer than a few sentences.
– Slow inference time — because GPT-3 is so large, it takes more time for the model to produce predictions.
– GPT-3 suffers from bias — all models are only as good as the data that was used to train them and GPT-3 is no exception.
So while GPT-3 is powerful, it still has limitations that make it far from being a perfect language model or an example of artificial general intelligence
CONCLUDING THOUGHTS

I started this piece with Alfred North Whitehead and I want to conclude with him, and the work of Shannon Vallor who is a philosopher of technology and holds the Gifford Chair in Ethics of Data and Artificial Intelligence at the Edinburgh Futures Institute. Her research projects focus on the impact of emerging technologies – particularly those involving automation and artificial intelligence – on the moral and intellectual habits, skills and virtues of human beings: our character.
She has worked with GPT-3 and has noted:
As brute force strategies go, the results are impressive. The language-generating model performs well across a striking range of contexts. Given only simple prompts, GPT-3 writes not just interesting short stories and clever songs, but also executable code such as web graphics.
GPT-3’s ability to dazzle with prose and poetry that appears entirely natural, even erudite or lyrical, is less surprising. It’s a parlor trick that its predecessor performed a year earlier, though its then-massive 1.5 billion parameters are swamped by GPT-3’s power, which uses 175 billion parameters to enhance its stylistic abstractions and semantic associations.
Yet the connections GPT-3 makes are not illusory or concocted from thin air. It and many other machine learning models for natural language processing and generating do, in fact, track and reproduce real features of the symbolic order in which humans express thought. And yet, they do so without needing to have any thoughts to express.
The hype around GPT-3 as a path to general artificial intelligence reveals the sterility of mainstream thinking about AI today. More importantly, it reveals the sterility of our current thinking about thinking.
She has produced a mountain of work on this which is just too much to summarise so I’ll just note a few of her major points.
A growing number of today’s cognitive scientists, neuroscientists and philosophers are aggressively pursuing well-funded research projects devoted to revealing the underlying causal mechanisms of thought, and how they might be detected, simulated or even replicated by machines. But the purpose of thought — what thought is good for — is a question widely neglected today, or else taken to have trivial, self-evident answers. Yet the answers are neither unimportant, nor obvious.
Vallor notes the neglect of this question leaves uncertain the place for thought in a future where unthinking intelligence is no longer an oxymoron, but soon to be a ubiquitous mode of machine presence, one that will be embodied in the descendants and cousins of GPT-3.
There is an urgent question haunting us, an echo from Alfred North Whitehead’s conclusion in 1911 that civilizations advance by expanding our capacity for not thinking: What thoughts do the civilized keep? Whitehead, of course, was explicitly talking about the operations of mathematics and the novel techniques that enable ever more advanced shortcuts to be taken in solving mathematical problems. To suggest that he is simply wrong, that all operations of thought must be forever retained in our cognitive labors, is to ignore the way in which shedding elementary burdens of thought often enables us to take up new and more sophisticated ones. As someone who lived through the late 20th century moral panic over students using handheld scientific calculators in schools, I embrace rather than deny the vital role that unthinking machines have historically played in enabling humans to stretch the limits of our native cognitive capacities.
Yet Whitehead’s observation leaves us to ask: What purpose, then, does thinking hold for us other than to be continually surpassed by mindless technique and left behind? What happens when our unthinking machines can carry out even those scientific operations of thought that mathematical tables, scientific calculators and early supercomputers previously freed us to pursue, such as novel hypothesis generation and testing? What happens when the achievements of unthinking machines move outward from the scientific and manufacturing realms, as they already have, to bring mindless intelligence further into the heart of social policymaking, political discourse and cultural and artistic production? In which domains of human existence will thinking — slow, fallible, fraught with tension, uncertainty and inconsistency — still hold its place? And why should we want it to?
To answer these questions, Vallor says we need to focus on what unthinking intelligence lacks. What is missing from GPT-3? It’s more than just sentience, the ability to feel and experience joy or suffering. And it’s more than conscious self-awareness, the ability to monitor and report upon one’s own cognitive and embodied states. It’s more than free will, too — the ability to direct or alter those states without external compulsion.
Of course, GPT-3 lacks all of these capacities that we associate with minds. But there is a further capacity it lacks, one that may hold the answer to the question we are asking. GPT-3 lacks understanding.
This is a matter of some debate among artificial intelligence researchers. Some define understanding simply as behavioral problem-solving competence in a particular environment. But this is to mistake the effect for the cause, to reduce understanding to just one of the practical powers that flows from it. For AI researchers to move past the behaviorist conflation of thought and action, the field needs to drink again from the philosophical waters that fed much AI research in the late 20th century, when the field was theoretically rich, albeit technically floundering.
Understanding is beyond GPT-3’s reach because understanding cannot occur in an isolated computation or behavior, no matter how clever. Understanding is not an act but a labor. Labor is entirely irrelevant to a computational model that has no history or trajectory in the world. GPT-3 endlessly simulates meaning anew from a pool of data untethered to its previous efforts. This is the very power that enables GPT-3’s versatility; each task is a self-contained leap, like someone who reaches the flanks of Mt. Everest by being flung there by a catapult.
GPT-3 cannot think, and because of this, it cannot understand. Nothing under its hood is built to do it. The gap is not in silicon or rare metals, but in the nature of its activity. Understanding does more than allow an intelligent agent to skillfully surf, from moment to moment, the associative connections that hold a world of physical, social and moral meaning together. To quote Vellor:
Understanding tells the agent how to weld new connections that will hold under the weight of the intentions, values and social goals behind our behavior.
Predictive and generative models like GPT-3 cannot accomplish this. It can’t randomly reverse its position every few sentences. Yes, it might effortlessly complete an essay assigned to it. But that is a sign not of GPT-3’s understanding, but the absence of it. To write it, it did not need to think; it did not need to struggle to weld together, piece by piece, a singular position that would hold steady under the pressure of its other ideas and experiences, or questions from other members of its lived world. The instantaneous improvisation of its essay wasn’t anchored to a world at all; instead, it was anchored to a data-driven abstraction of an isolated behavior-type, one that could be synthesized from a corpus of training data that includes millions of human essays, many of which happen to mention consciousness. GPT-3 generated an instant variation on those patterns and, by doing so, imitated the behavior-type “writing an essay”.
Understanding is a lifelong labor. It is also one carried out not by isolated individuals but by social beings who perform this cultural labor together and share its fruits. The labor of understanding is a sustained, social project, one that we pursue daily as we build, repair and strengthen the ever-shifting bonds of sense that anchor our thoughts to the countless beings, things, times and places that constitute a world. It is this labor that thinking belongs to. One more quote from Vellor and then I’ll sum up:
Thus, when we talk about intelligent machines powered by models such as GPT-3, we are using a reduced notion of intelligence, one that cuts out a core element of what we share with other beings. This is not a romantic or anthropocentric bias, or “moving the goalposts” of intelligence. Understanding, as joint world-building and world-maintaining through the architecture of thought, is a basic, functional component of human intelligence. This labor does something,without which our intelligence fails, in precisely the ways that GPT-3 fails.
If you look at extremist communities, especially in the social media era, it bears a disturbing resemblance to what you might expect from a conversation held among similarly trained GPT-3s. A growing tide of cognitive distortion, rote repetition, incoherence and inability to parse facts and fantasies within the thoughts expressed in the extremist online landscape signals a dangerous contraction of understanding, one that leaves its users increasingly unable to explore, share and build an understanding of the real world with anyone outside of their online haven.
Thus, the problem of unthinking is not uniquely a machine issue; it is something to which humans are, and always have been, vulnerable. Hence the long-recognized need for techniques and public institutions of education, cultural production and democratic practice that can facilitate and support the shared labor of understanding to which thought contributes.
The very things we needed – we gutted. Had more nations invested in and protected such institutions in the 21st century, rather than defunding and devaluing them in the name of public austerity and private profit, we might have reached a point by now where humanity’s rich and diverse legacies of shared understanding were at least partially secured around the globe, standing only to be further strengthened by our technological innovations. Instead, systems like GPT-3 now threaten to further obscure the value of understanding and thinking.
Yes, humanity has reached a stage of civilization in which we can build space stations, decode our genes, split or fuse atoms and speak nearly instantaneously with others around the globe. Our powers to create and distribute vaccines against deadly pandemics, to build sustainable systems of agriculture, to develop cleaner forms of energy – all achievable.
But the real keys to our future – to avert needless wars, to maintain the rule of law and justice and to secure universal human rights, to achieve real understanding are gone. We are left to the vagaries of increasingly unsteady and unthinking hands and minds. We’ve taken Whitehead’s words to the max.

One Reply to “The Language Machines : a deep look at GPT-3, an AI that has no understanding of what it’s saying.”